WXB-009
[Paper] Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
训练过程仿照 Qwen-VL 进行(3 stages),模型架构设计也与它类似。唯一的区别是,Janus 对 understanding / generation task 用了 不同的 image encoder。
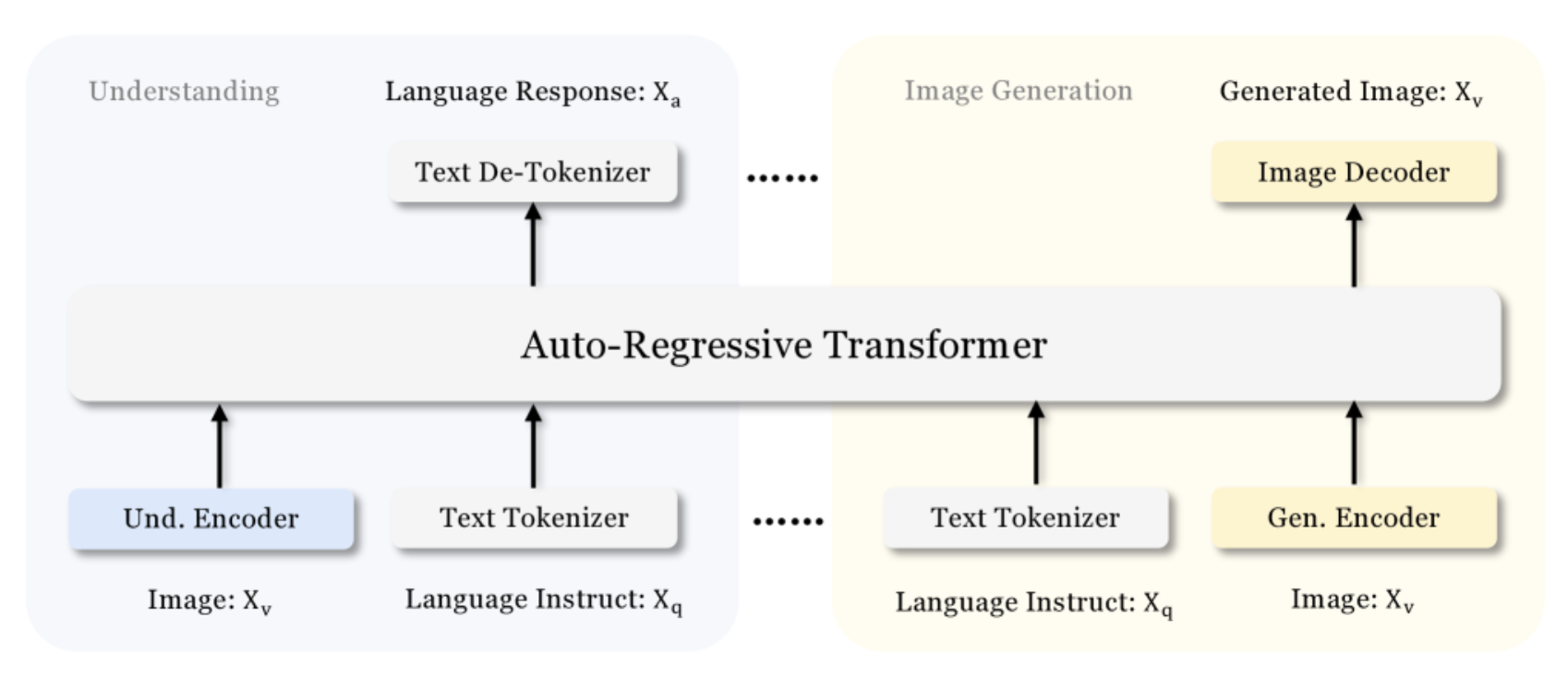
- Understanding Encoder: 用 SigLIP。
- Generation Encoder:用 VQVAE from LlamaGen。
- 注意这是一个 autoregressive generative model,意味着 Janus 的所有 generation 都是 AR 的。