WXB-007
[Paper] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL 是开源 VLM 的典范之作,主要解决 visual understanding 的 task,并没有处理 generation。
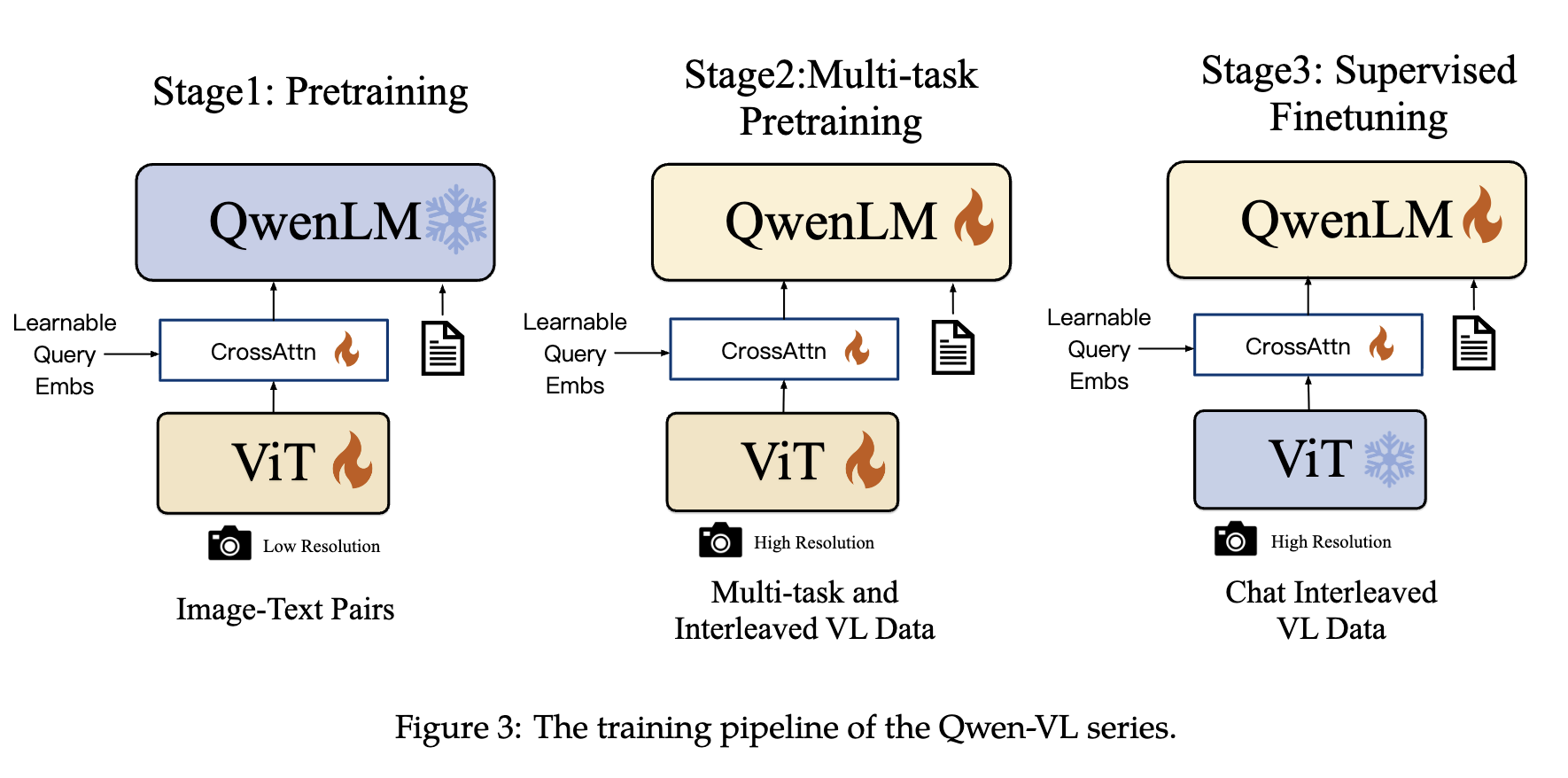
Architecture
对一张输入的图片,先过一个 ViT (load pretrained weights from Openclip ViT-bigG) 得到同样大小的 feature。然后把这些 feature 作为 LLM generation 的前缀,用 Decoder-only LM (load pretrained weights from Qwen-7B) 生成回答。
注意下图中还有一个 “CrossAttn” 的 block,叫做 Position-aware Vision-Language Adapter。
Paper story: 因为我们想要限制 image token 数量恰好为 256,所以我们学一个 cross-attention block 以及 256 个 query token,就能做到这一点。
疑惑点是为什么要固定 token 数量。
- Model Size: ViT 1.9B, Adapter 0.08B, LLM 7.7B。一共 9.6B。
Training Stages
Stage 1: Pretraining ViT
先用 captioned text-image dataset 做 LLM captioning 的 loss。固定 LLM,只训 ViT。这部分的训练让 ViT 输出的 embedding 能够 align with text tokenizer。
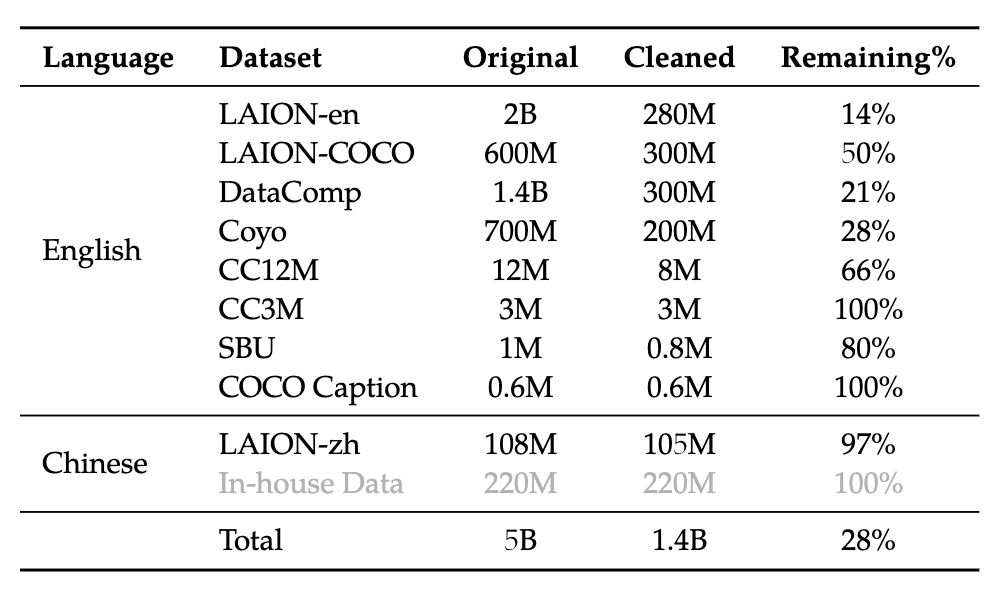
数据集如下;只训练 1 epoch。据 paper 的说法,dataset cleaning 对我们是 feasible 的:
- Removing pairs with too large aspect ratio of the image
- Removing pairs with too small image
- Removing pairs with a harsh CLIP score (dataset-specific)
- Removing pairs with text containing non-English or non-Chinese characters
- Removing pairs with text containing emoji characters
- Removing pairs with text length too short or too long
- Cleaning the text’s HTML-tagged part
- Cleaning the text with certain unregular patterns
Stage 2: Multi-task Pretraining
这部分我们把所有 parameter 都 activate。Task 从原来的 captioning 扩展为 multi-task,除了之前的 captioning 还有 pure-text autoregression, visual question-answering (VQA), OCR, 以及 segmentation (让 LLM 以固定形式输出 bounding box)。
在这个阶段 image resolution 提高两倍 ($224 \to 448$)。
Stage 3: Instruction Fine-tuning
为了支持用户多轮询问,用 internal dataset 做 SFT。数据量约为 350K。