WXB-011
[Paper] Efficient Streaming Language Models With Attention Sinks
Attention Sink 概念的提出者。
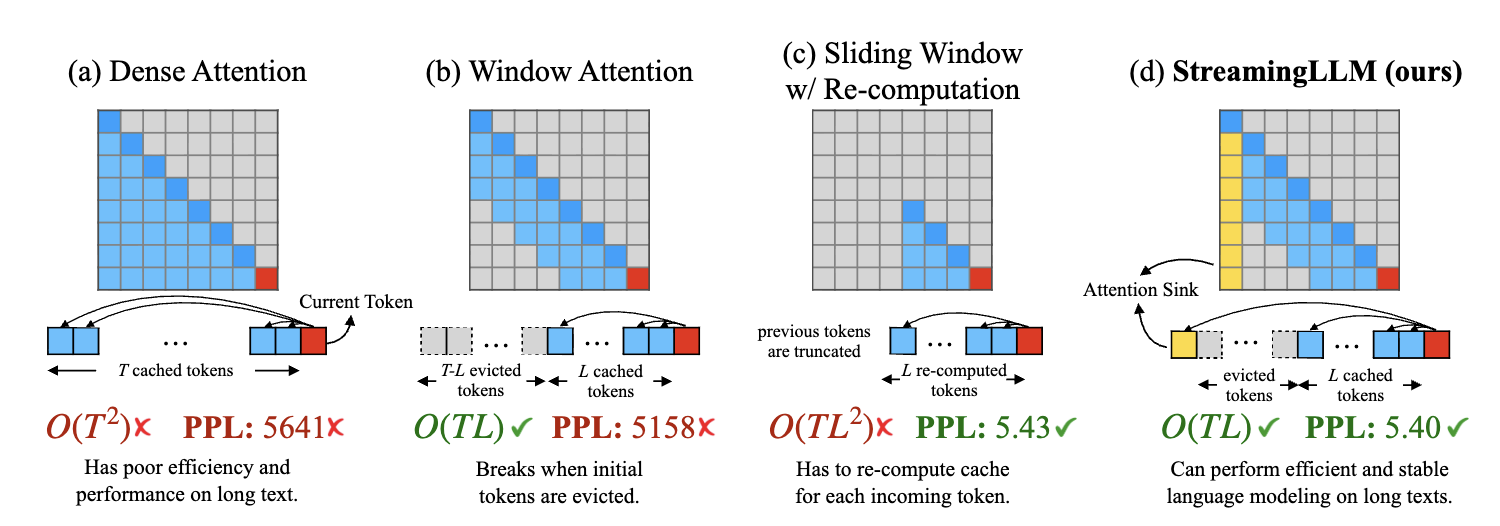
首先考虑 post-training efficient attention computation。最直接的方法是 sparse attention,也就是选择性地计算注意力矩阵中的一部分元素,从而减少计算量。
最直接的方法是 window attention,即每个 token 只与其前后一定范围内的 token 进行注意力计算;但是如果不 fine-tune 的话会直接 fail。
Attention Sink
作者 profile 了一下一个 pretrained LLM 每一层的 attention weight (即 softmax 之后的 attention scores):
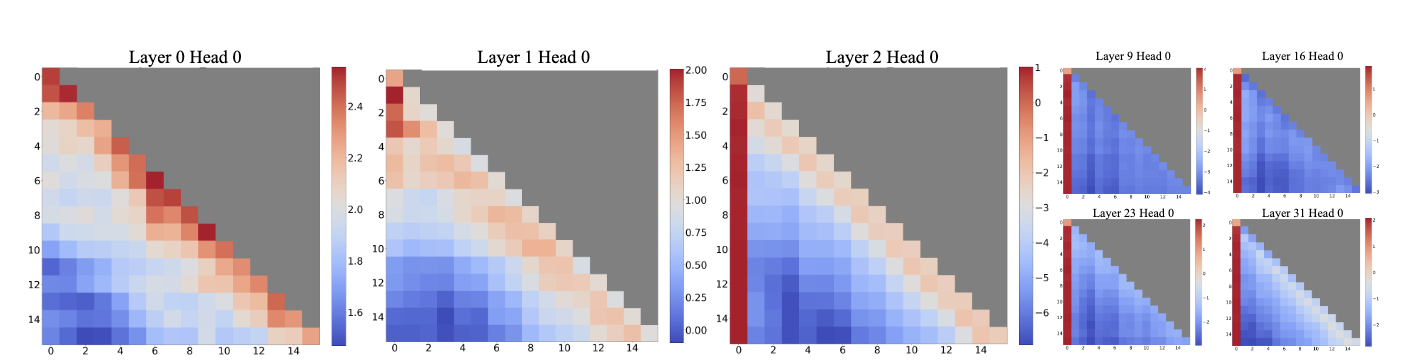
发现,在 lower layer,attention weight 确实接近 window attention 的形式;但是在 higher layer,绝大部分的 weight 都被分配到了第一个 token 上。
于是,在保留第一个 token 并做 window attention (StreamingLLM), 就能刷点,如下图。
以下是个人理解。为什么会出现 Attention Sink?首先是 feasibility,因为有了 positional embedding,模型可以区分不同位置的 token。其次是为什么模型要这样做:既然每个 token 都可以注意到 first token,那么它的地位就是“吸收 attention weight”——每个 token 在每一层都必须分配总和为 $1$ 的 weight,如果加入了 attention sink,那么这个 “$1$” 的限制就会变成 “$\le 1$”。
实际的现象是,模型在前几层先通过 local attention 来整合局部信息,然后之后的层把绝大部分 weight 都放在 sink 上,其他 weight 的作用是对特征进行“微调”。
Ablations
- 在每个训练数据前面加入 $4$ 个特殊 token (比如
\n),发现 attention sink 现象仍然存在,模型 PPL 和 baseline 相当。 -
如果 softmax 使用 softmax-off-by-one
\[\text{softmax}_1(x_i) = \frac{\exp x_i}{1+\sum_j \exp x_j},\]能够显著缓解 attention sink 现象,但是模型仍然会注意到最初的若干 token。
- 如果我们在 pretraining 的时候就 prepend 一些 learnable tokens,模型会学会把 attention sink 放在这些 token 上。实验结果是 loss 更低,PPL 也更好,attention weight 的分布也更清晰。
- loss 更低的原因是,如果 first token 既充当一个 sink,又要 encode 语义信息,会有冲突,并且不适合 long-context position embedding interpolation。把 sink 的作用 isolate 出来就能解决这些问题。
