WXB-010
[Paper] SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
一篇很硬核的 paper。从一个全新的架构 Linear Attention 开始,re-design 了 autoencoder,换了 inference sampler,又做了一些硬件上的优化 (kernel fusion)。最后在比 baseline 低 $\sim50$ 倍的 latency 下做到了 comparible 的效果。
个人认为里面的很多 practice 值得我们借鉴。
Architecture Overview
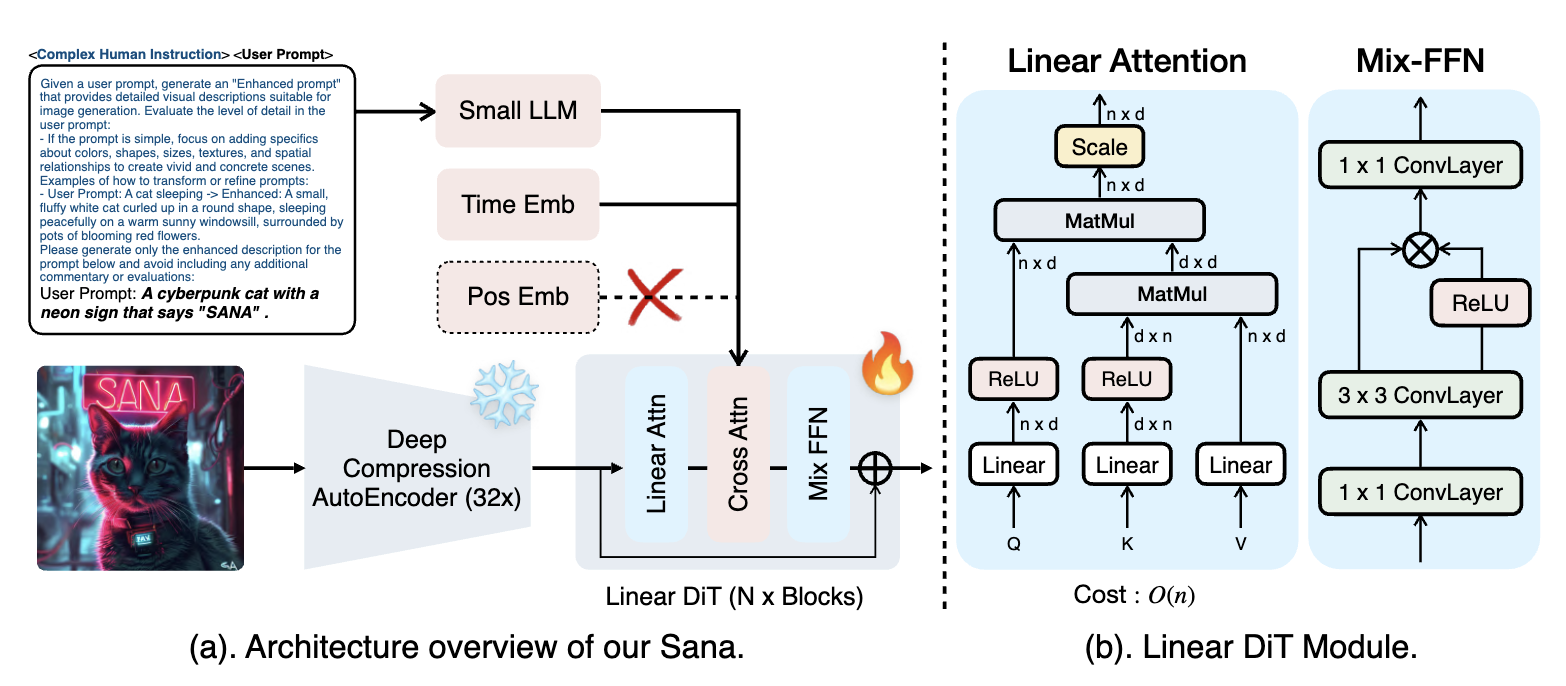
Autoencoder
还是用的 Latent Diffusion Model,但是把压缩比从 $8\times$ 提升到了 $32\times$ (latent channel $C$ 从 $4$ 提升到 $32$),并且 patch size 为 $1$。Setting: F32C32P1。
深意是,现在 T2I model 的 bottleneck 不在 autoencoder 的 reconstruction 上,而是在 diffusion model 的 capacity 上。所以可以用更高的压缩比来节省计算。所以一方面要提升压缩比例;其次众所周知 patchify 很影响 diffusion training,所以把 patchify 的代价转移到 AE 上是赚的。
Linear Attention & Mix-FFN
直接把 Attention 换成了复杂度 $O(N)$ 的 linear attention。其最初出自 ReLU Linear Attention (on LLM),我们可以把 softmax 替换成对 $Q,K$ 做 ReLU:
\[O_i=\sum_{j=1}^L \frac{\text{ReLU}(Q_i) \cdot \text{ReLU}(K_j)^T}{\sum_{m=1}^L \text{ReLU}(Q_i) \cdot \text{ReLU}(K_m)^T} V_j.\]这样的话我们可以 pre-compute
\[S=\sum_{j=1}^L \text{ReLU}(K_j)^T V_j\]以及
\[Z=\sum_{m=1}^L \text{ReLU}(K_m),\]最后 output vector 就是
\[O_i=\frac{\text{ReLU}(Q_i) \cdot S}{\text{ReLU}(Q_i)\cdot Z^T}.\]个人觉得这里能 work 可能要归功于 AE 的高压缩比。但是还是 observe 到 training efficiency 下降,所以又引入了 Mix-FFN——把原来的 SwiGLU-MLP 中的如下部分:
\[y = \text{act}(Wx+b) \odot (W'x + b')\]里的 $W,W’$ 替换为 $3\times 3$ convolution。这样能够引入 local inductive bias,partially 弥补 linear attention 带来的 global context 缺失。
在做了这个替换之后,我们发现可以不用 positional encoding 了 (因为 conv 已经 encode 了位置信息, if with zero padding)。
Comment: 越来越像 convolution-based 了…
Other Tricks
- Text Encoder: 把大家常用的 T5-XXL 换成了 Gemma2-2B。提到了 decoder-only model 的 embedding 会有更大的 variance,所以先 apply normalization 会更好。
- Complex human instruction (CHI): 这个没看,放个 reference:LiDiT.
- Recaptioning: 用众多 VLM 一起 caption,然后用 CLIP similarity 为参考进行 sample (分数高的以更高概率取到)
- Resolution Pre-training: 先在 $512$ resolution 上训练,然后再 finetune 到 $1024$。提到这样能提升 training stability。
- Sampler: DDPM-Solver++,用 FM 的 formulation ($\alpha_t=1-\sigma_t$)。
Impl. Detail
- 0.6B: width 1152, depth 28, FFN 2880, num heads 36
- 1.6B: width 2240, depth 20, FFN 5600, num heads 70
值得注意的是 1.6B 的 depth 反而更小 (paper 中说 depth 维持在 $20$ 到 $30$,不要 scale 它)。从 FID / GenEval 上两个模型并无太大差别。
数据集是 internal 的。急急急
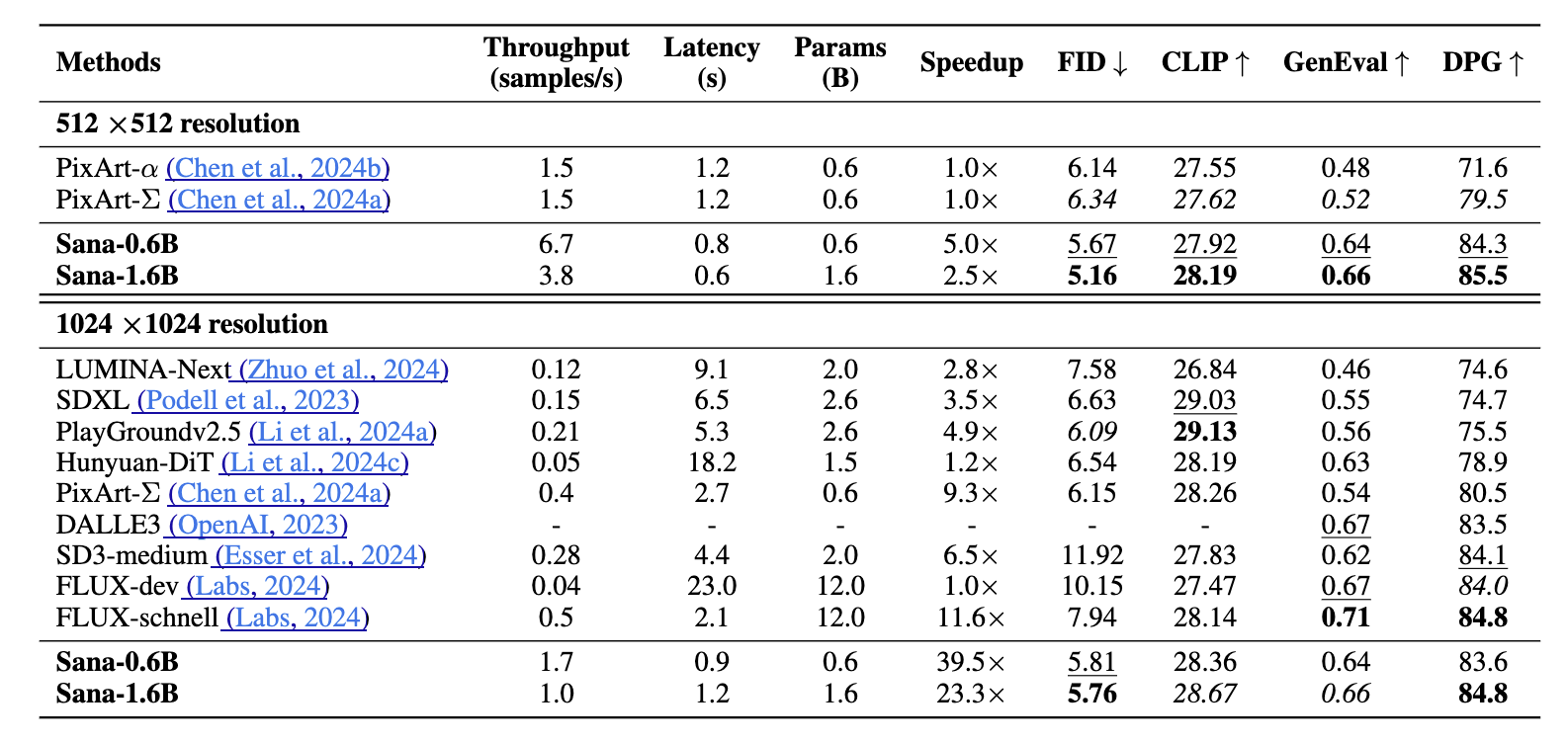
System-Level Comparison