ZKY-001
[Paper] SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation
SANA
sana 是一个工业界模型,没有公开使用的数据集和更具体的训练细节。
使用了压缩比例更高的 32x AutoEncoder,使用的是它们自己的 DC-AE-F32C32。架构如下。
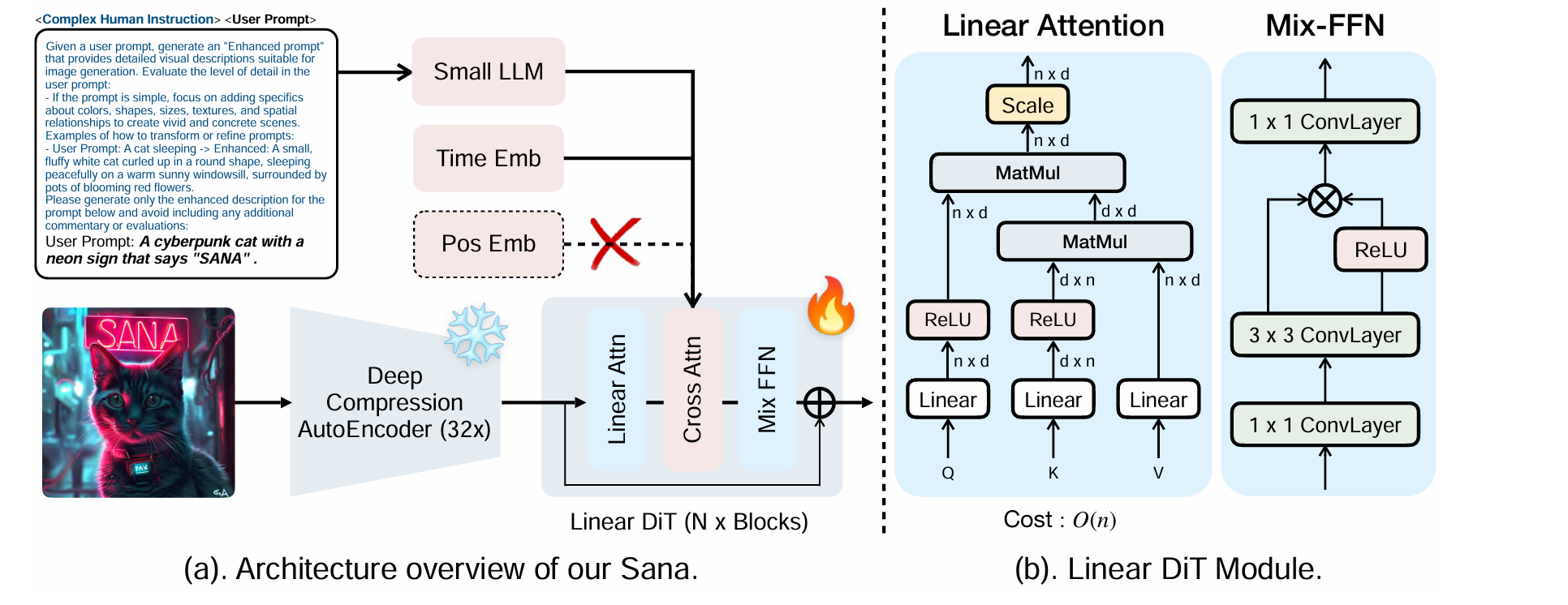
SANA-Sprint
TrigFlow & sCM
类似 Diffusion 和 Flow Matching,我们定义 $x_t = \cos t\cdot x + \sin t \cdot \epsilon$,然后训练模型预测 $v = \frac{dx_t}{dt} = -\sin t\cdot x+\cos t\cdot \epsilon$。
sCM 就是在 TrigFlow 的基础上加入 Consistency Model。
TrigFlow 和 Flow Matching 的转换
首先 Sana 是一个 Flow Matching 模型,而为了使用基于 TrigFlow 的 sCM 的训练 Pipeline,我们需要在 TrigFlow 模型和 Flow Matching 模型之间转换。
在 $t$ 时刻,我们目前有一个 noisy 图片 $x_{t}$,然后我们希望预测满足 $\sin t\cdot x+\cos t\cdot \epsilon=x_t$ 的 $(x,\epsilon)$ 的 $\mathbb E(-\cos t\cdot x+\sin t\cdot \epsilon)$。可以通过调用把 $x_t$ scale $\frac{1}{\sin t+\cos t}$ 倍之后的 Flow Matching 模型预测出来 $x$ 的期望,从而预测出来 $x_t$ 在 TrigFlow 上的速度。
Dense Time Embedding
这是一个 sCM 原论文提出过的一个方法。
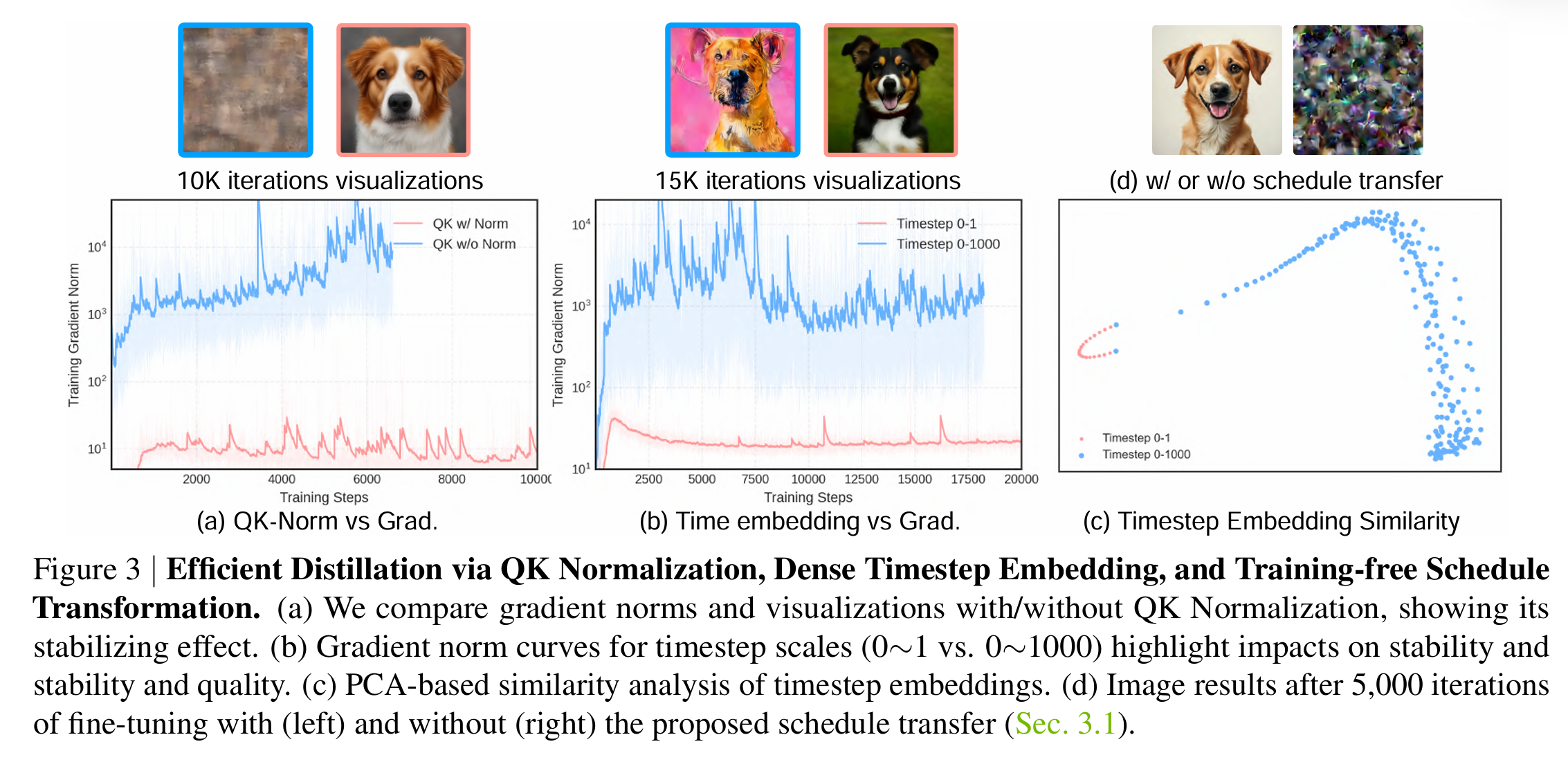
SANA 原本论文中的 Time Embed 是 $\text{embed}(1000t)$。由于 sCM 需要对 $t$ 求梯度,这一项的存在会给梯度乘 $1000$,让梯度变得极不稳定。
因此我们将 Time Embed 改为 $\text{embed}(t)$。为了让原来的 SANA 模型能够接受这个 Time Embed,论文作者称只需要微调原来的 SANA 模型 5k 个 iterations。
QK-Norm
在 sCM 训练中,gradnorm 经常超过 $10^3$。论文在微调时给 self-attention 和 cross-attention 的 Query 和 Key 都增加了 RMS normalization。使用微调后的模型来进行后续的 sCM 训练能够让 gradnorm 变得更加平缓。
LADD loss
我们采用类似 GAN 的思路:训练一个 discriminator $D$,其中 $D$ 使用了 “frozen teacher”,即原始的多步生成的diffusion模型,作为 backbone。在这个 backbone 的基础上,$D$ 对其中的每一层 feature 都长出一个 head 作为 discriminator。
训练时,我们采样真实图片 $x_0$,加噪获得 $x_t$ 并让我们的生成模型 $G$ 去噪获得 $\hat x_0$。然后我们选取 noise level $s$,给 $x_0$ 和 $\hat x_0$ 分别加噪为 $x_{s}$ 和 $\hat x_s$,然后让所有的 Discriminator 区分噪声和图片。
(个人理解)这么做是为了让 Discriminator 的反馈更加丰富,使得训练更加稳定。
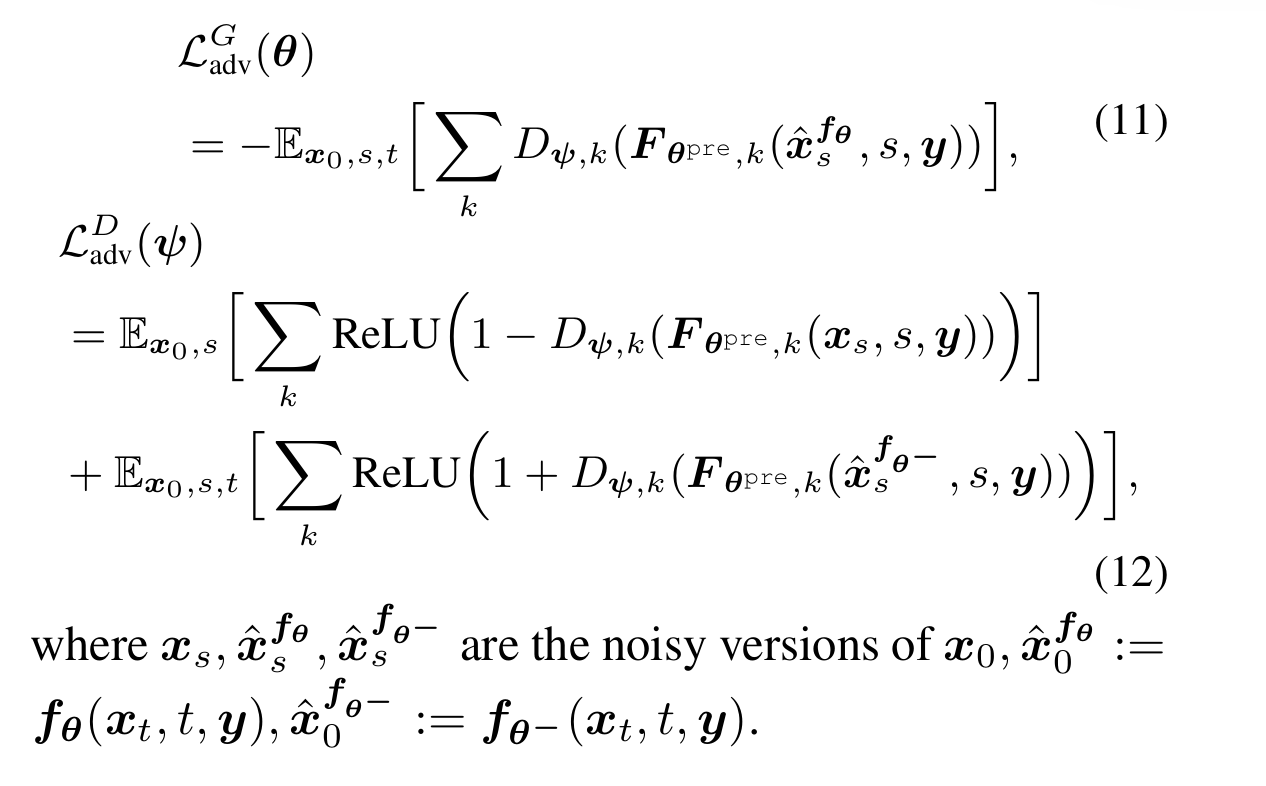
论文中还采用了Additional Max-Time Weighting 方法来采样时间步 $t$。例如,其将一半的采样用于 $t=\frac{\pi}{2}$,即从纯噪声纯噪声。具体感觉可以先不管。

