WXB-008
[Paper] Tuna: Taming Unified Visual Representations for Native Unified Multimodal Models
Meta 的一篇 UMM (Unified multimodal models)。
Unified multimodal models (UMMs) aim to jointly perform multimodal understanding and generation within a single framework.
UMM 需要同时支持 image / video understanding, image / video generation, image editing, 等等。其终极目标是实现 unified representation。
仿照 Qwen-VL 的方法,首先 load 一个 pretrained LLM (Tuna 使用了 Qwen-2.5)。
Image token 和 text token 放到一个序列里处理。对于 image token 采用 bidirectional attention, 对 text token 使用 causal。这样可以支持多种任务,如下图。
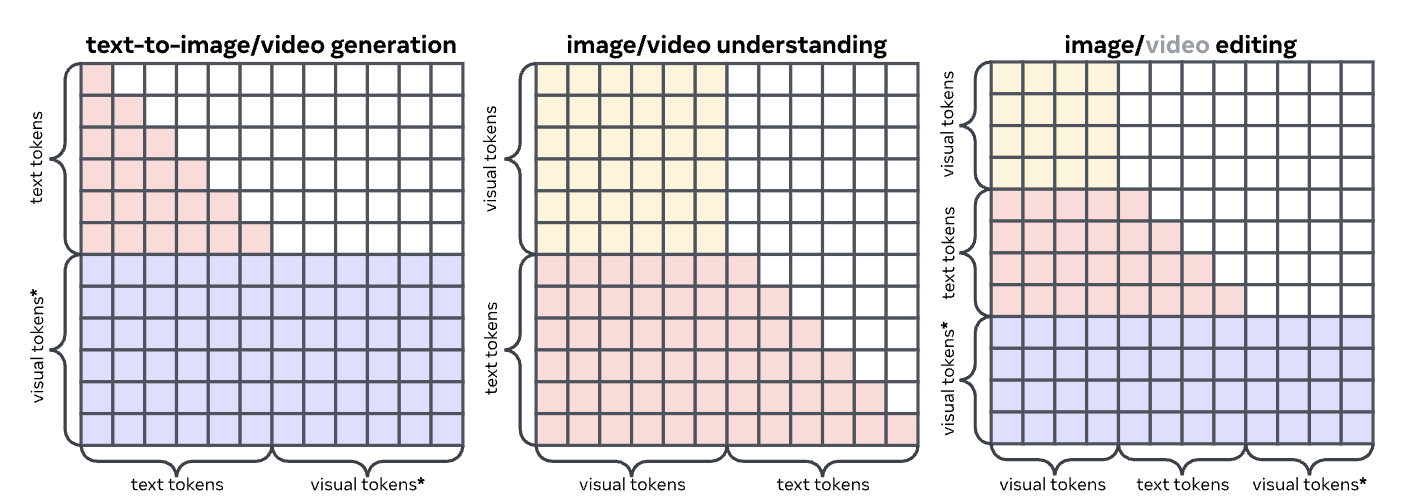
Architecture
Visual Encoder
- Pretrained VAE $\phi$ (Wan 2.2 VAE).
- Pretrained representation model $\psi$ (SigLip 2).
Encoder 架构:首先过 VAE $\phi$,然后过 $\psi$,最后用一个可训练的两层 MLP $\mathcal M$。
在 $\phi$ 和 $\psi$ 的中间,将 $\psi$ 的 patch embedding layer 替换为可学参数。(原来 $\psi$ 的 patch 是 $16\times 16$, 同时 $\phi$ 的 downsample rate 也是 $16$,所以这个 embedding layer 是一个 $1\times 1$ convolution)
LLM & FM Head
- Understanding: 对 LLM 输出的 pre-logits, 训一个 LLM head 用于输出 token distribution。
- Generation:对 LLM 输出的 image tokens $I_{:L}$, 再过一个和 LLM 相同架构的 flow-matching head (condition on $I$)。
Training Stages
和 Qwen-VL 一样,是 3-stage training。
- Stage 1: fix LLM, train visual encoder and heads。只用两种任务: image captioning 和 text-to-image generation。
- Stage 2: unfreeze LLM,用更多的任务训。引入 video: 本质上就是 concat 每一帧的 image。
- Stage 3: instruction fine-tuning。
Qualitative Results
Image Generation

Video Generation

Image Editing
