SQA-043
[Paper] Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
本文提出了在 VLM 做 RL finetune 的方法, 对应于 RLVR. 这篇也是 Saining 和 Lecun 的文章
简单来说道理很简单,就是搭建了一些 environment, 设计了能自动计算的 reward, 然后使用 PPO 算法 finetune
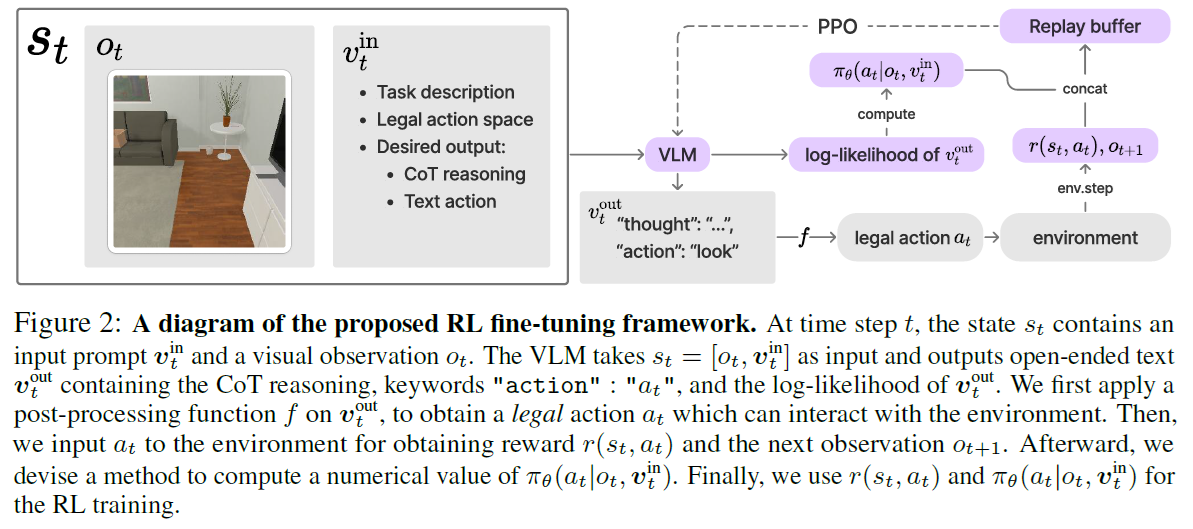
其中可以看到使用了经典的 offline learning (replay buffer)
Environment
可能还是因为算力原因,本文只采用了 7B 的 VLM 以及一些比较简单的环境

其中前四个是关于卡牌/数字的,都作为 vision 输入. Task description 是 language 输入
最后一个, ALFWorld, 是一个比较复杂的环境, 给出了图片以及一些文本输入, 需要模型理解环境并且输出 action. 似乎是一个经典的具身环境

其中有一个比较神秘的点,是关于 action. 在比如算24点的任务中,整个式子被拆成了多个 action,见下图

不知道为什么,可能是模型太菜,可能是想要模拟 multi-turn reasoning
并且这里的 setting 应该是没有 feedback 和 history 的,模型每次只能看到当前的 observation. 这看起来和之后的做法不太一样
所有 action 都是 text output.
Training Details
首先,如果某次输出的 action 不是 legal 的,那么会选择做一个 random action (做 exploration), 不知道是否合理
模型被 prompt 来做 CoT
其次是 policy 概率项的估计 $\log\pi_{\theta}(a_t\mid o_t,v_t^{in})$
首先,我们注意到 PPO 并不需要所有可能的 action 的和为 1, 毕竟用了 log prob.
在这种情况下,最简单的方法是直接估计整个输出的概率。但是作者们发现一个很大的问题:就是输出的概率很可能被 CoT 的概率主导,而 action given CoT + input 的贡献却很小。这挺合理的,毕竟 CoT 很长,log prob是一个很小的负数。
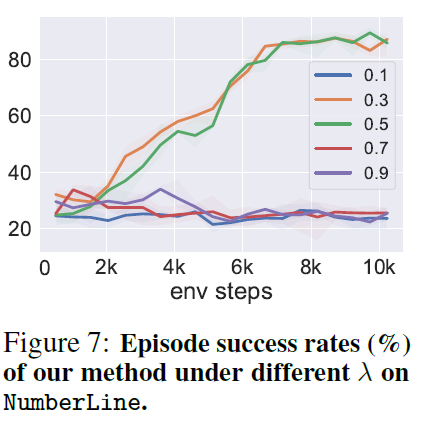
于是作者提出如下估计我们 action 的概率:
\(\lambda\log\pi_{\theta}(v^{think}_t\mid o_t, v_t^{in}) + \log\pi_{\theta}(a_t\mid o_t, v_t^{in}, v^{think}_t)\) 加入了一个平衡系数 $\lambda$. 并且作者说这个对最终结果巨重要。RL 是这样的。一般选取 $\lambda\in[0.2, 0.5]$.
Results
本文除了 Llava-7B 以外, 还提供了一个 CNN+RL 的 baseline. 虽然我没仔细看这个是什么。但总之本文的方法的结果超过了 GPT-4 + Gemini
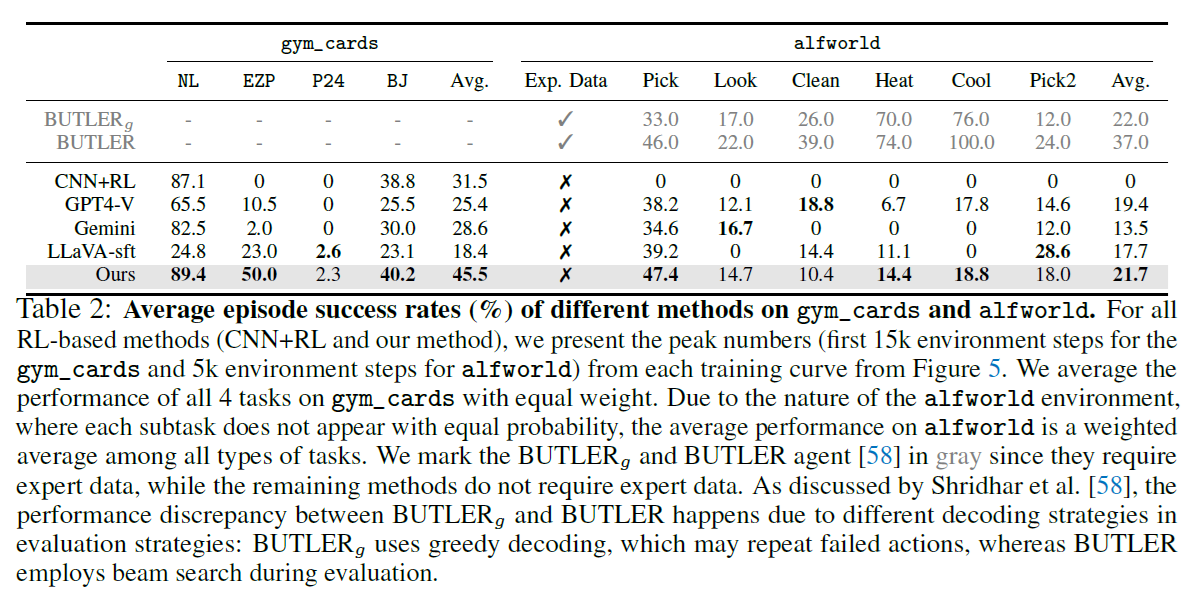
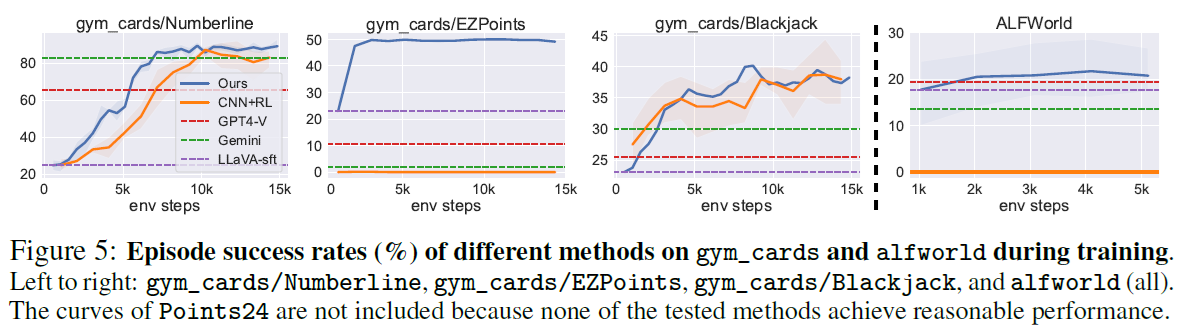
Role of CoT
作者发现 CoT 对于 RL finetune 非常重要。没有 CoT 的话,模型的表现巨差。