SQA-039
[Paper] SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
一个 Saining 的作品
本文的 message 很明显:主要比较了 SFT 和 RL,两种主流的 post-training 方法是否能 generalize
Backgrounds
经典的 finetune 步骤是,先用 SFT (supervised finetune) 让模型能输出特定结构的答案,然后用 RL (reinforcement learning) 来做 alignment / specific task
这里我们先只考虑 verifiable reward 的情况, 并且只考虑 PPO 算法
特别注意, DeepSeek-R1 证明了可以直接用 RL 来训练模型来输出特定结构的答案,而不需要 SFT 作为预训练。但是这个方法很依赖于 base model. 比如菜一点的 Llama 就做不到,很容易 RL 直接 fail
本文除了 LLM 之外,还研究了 VLM (vision-language model)。二者的结论是类似的
Setup
本文主要考虑了两种任务:第一个是 算 24 点, 训练输入是 1-10 内的数字, JQK 都算 10. 在测试 generalization 的时候会考虑 OOD 输入,也就是 JQK 算 11/12/13。
模型被要求直接输出最终答案,好像不允许 CoT。这样可以生成 SFT ground truth
同时还有一个 vision 变种,就是图片里面放四个卡牌,模型需要 recognize + 计算. 这里的 generalization 测试是训练的时候只用黑色卡片,测试的时候用红色卡片
第二个任务我不熟悉,感觉像是认路能力,也有 text + vision 两个变种。XIBO 能做对吗?
Sequential Revision
我们可以给模型多次尝试的机会。如果某次 fail 了,那么会用一个对话的形式继续让模型再试一次。
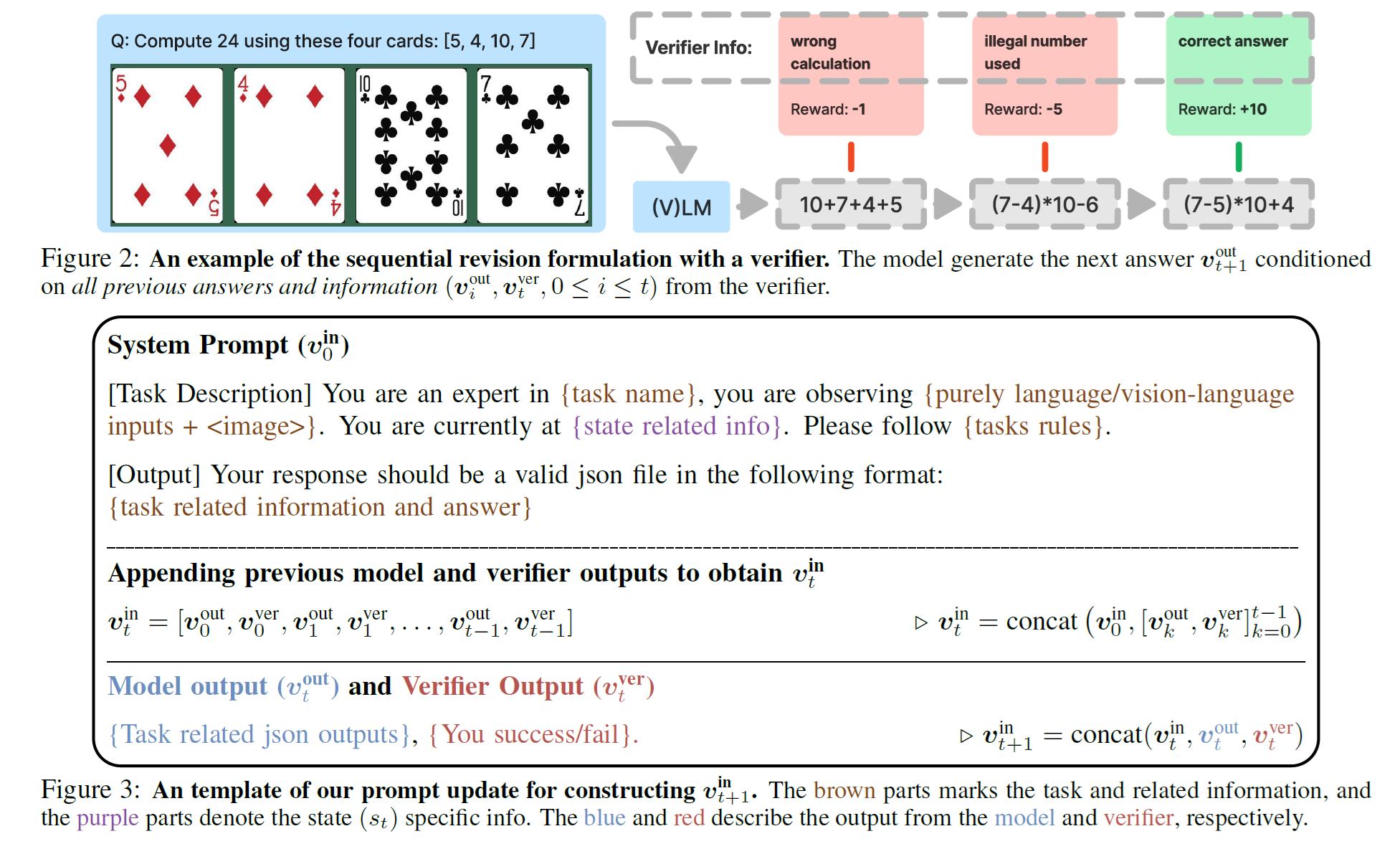
当然这仅限于 train time. Test time 只能给模型一次机会
Results
SFT Memorizes, RL Generalizes
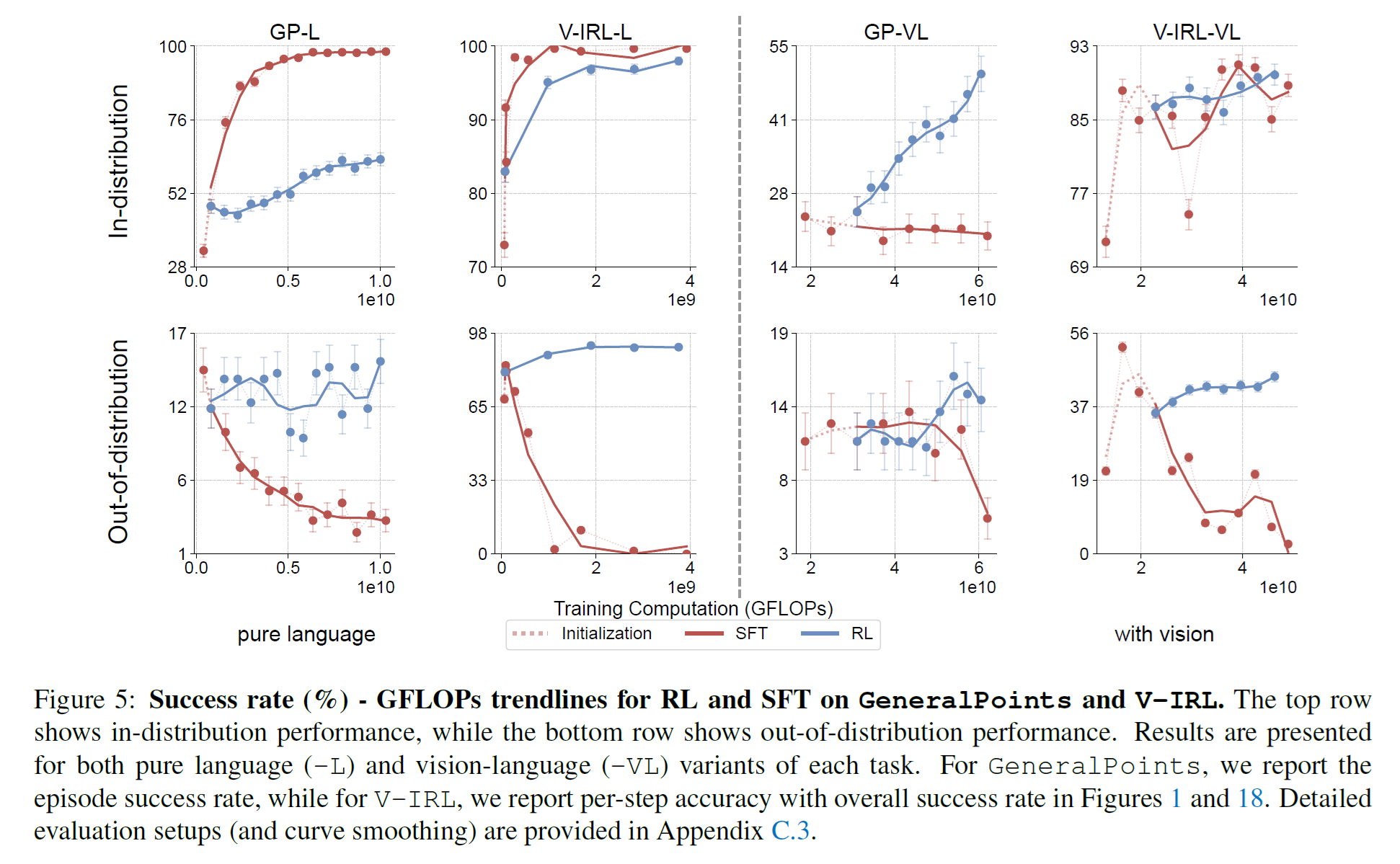
这里 GeneralPoint 表示 24 点。可以看到 SFT 在 ID 上表现很快就很高,但是 OOD 越来越低. 反而 RL 能 generalize 得很好
RL can improve vision recognition
做 RL 还可以让 recognition accuracy 提升, 但是 SFT 反而会降低 recognition accuracy
SFT is necessary, when base model does not follow instruction
作者发现 Llama-3.2-Vision-11B 非常不听话,不会遵循 instruction 来输出答案。这个时候 RL 是完全 fail 的,必须先用 SFT 来让模型学会输出特定格式的答案
侧面体现了 DeepSeek-V3 比较吊
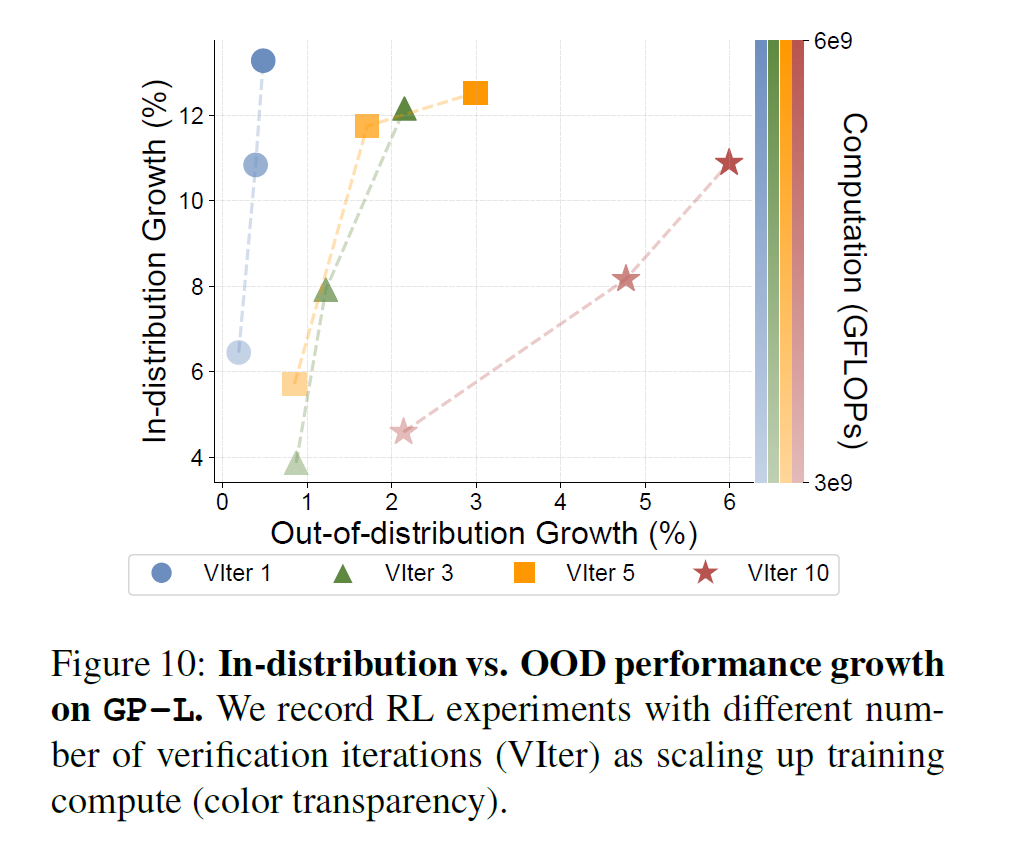
Scaling up Verification improves Generalization
这就是说,我们多让模型 try 几次,能提升 generalization 能力更多。ID 的表现最终都可以提升到类似的值,但是对于 OOD 来说,try 越多提升越大