SQA-038
[Paper] Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
Nvidia 又一篇大作
这篇文章提出了使用模型内置的概率函数作为 discriminator 来做 finetune 的方法,效果十分显著
Background
MLE 的训练目标等价于最小化 Forward KL:
\[\max_{\theta} \mathbb{E}_{x \sim p_{data}} [\log p_{\theta}(x)] \quad \Longleftrightarrow \quad \min_{\theta} D_{KL}(p_{data} \| p_{\theta})\]比如 diffusion model, VAE, AR 等。缺点是,这样的 forward KL 会导致 mode-covering 行为,生成的样本经常很糊 通常都是使用 guidance 来改善生成质量
相比来说, GAN 的训练目标等价于最小化 Reverse KL. 这样能生成更加清晰的样本
Diffusion as Discriminator
注意到我们可以用 ELBO 来估计数据的 log likelihood:
\[\log p_{\theta}(x) \geq C - \mathbb{E}_{t\sim p(t)} \left[w(t)\|\epsilon_{\theta}(x_t, t)-\epsilon\|^2\right]\]虽然并不知道这样的概率估计算不算准确。但甚至这个都需要对 $t, \epsilon$ 做积分才能估计一个数据点的概率。
先看看我们的目标: 我们希望优化 GAN discriminator loss:
\[\max_{\theta} \mathbb{E}_{x \sim p_{data}} [\log d_{\theta}(x)] + \mathbb{E}_{x \sim p_{\theta_{ref}}} [\log (1-d_{\theta}(x))]\]其中,$\theta_{ref}$ 是我们的 reference model, 也就是未 finetune 的,固定的 diffusion model
这样的 self-play 会进行多轮,每轮更替 reference model
其中如何 parameterize discriminator 呢?注意到最优的 discriminator 满足:
\[d^*(x) = \sigma\left(\log \frac{p_{data}(x)}{p_{\theta_{ref}}(x)}\right)\]所以我们令
\[d(x) = \sigma\left(\log p_{\theta}(x) - \log p_{\theta_{ref}}(x)\right)\]这样 $p_{\theta}$ 的最优就是 $p_{data}$.
现在回到如何 evaluate $p_{\theta}(x)$ 的问题。经过一番推导,我们发现这个 loss 有一个上界,利用 Jensen 不等式:
\[\mathcal{L}(\theta) \leq -\mathbb{E}_{t, \epsilon}\left[\mathbb{E}_{x \sim p_{data}} \log\sigma(\Delta)+\mathbb{E}_{x \sim p_{\theta_{ref}}} \log(1-\sigma(\Delta))\right]\]其中 $\Delta=-w(t)(|\epsilon_{\theta}(x_t, t)-\epsilon|^2 - |\epsilon_{\theta_{ref}}(x_t, t)-\epsilon|^2)$.
相当于,不知道为什么换一个期望的顺序。这样我们的 loss 就可以直接估计了。但其实就知道这个有多少误差。效果好就行了,哈哈
Implementation
注意到 sigmoid 激活函数必定有一个巨大的问题,就是 scale 要控制的正正好,否则梯度会消失
这时候聪明的作者就给所有地方加了一个 weight, 这有道理吗?
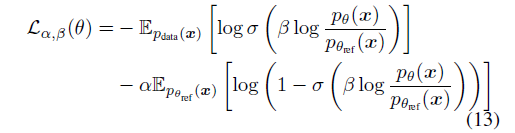
个人不知道为什么 $\alpha$ 有道理.
无论如何,通常的取值是 $\alpha\in[0.5, 50], \beta\in[0.01, 0.1]$. 作者说在很大一个跨度里面都能 work
Results and Experiments
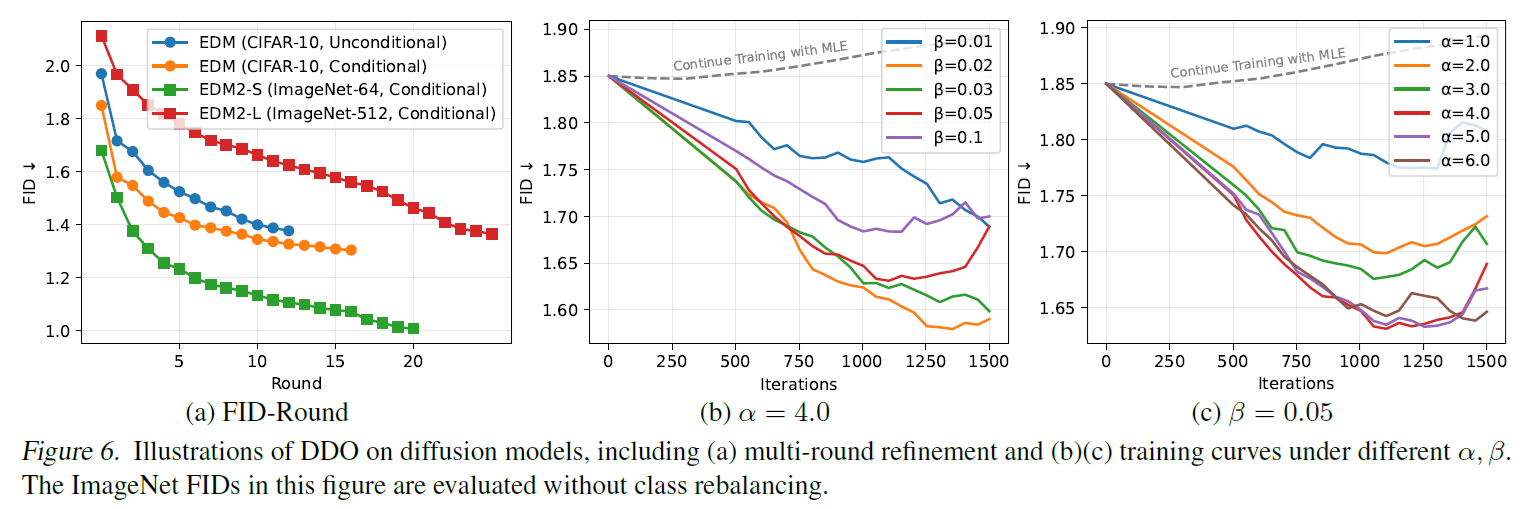
首先可以看到这样的 finetune 涨点很快,甚至有的两个 round 就可以涨很多, 而且调完基本不需要 guidance, 非常爽
1.38 / 1.30 CIFAR10
0.97 ImageNet 64
1.26 ImageNet 512
根本不是人
同样的作者也对 VAR 做了 finetune, 效果提升非常显著.
Comment
感觉缺点是每一轮需要模型重新生成等同多的图片. 看 appendix 每一轮在 ImageNet 上 train 5 epoch, 感觉对生成 overhead 还是很大的