SQA-035
[Paper] Any-Order GPT as Masked Diffusion Model: Decoupling Formulation and Architecture
这篇 paper 的写法比较偏理论,看着略恶心,不过实验还是不少的.
Background
目前最火的两个语言模型,除了 AR 就是 diffusion. 本文研究的是 masked diffusion
简单回顾 diffusion 看这里:
Masked Diffusion
这里采用的加噪过程是随机 mask 掉随机位置的token (换成 [MASK] token) 更具体的,对时间 $t\in[0, 1]$, 每个 token 以 $t$ 的概率独立变成 [MASK] 训练使用的 loss 为:先随机 sample $t$, mask, 然后使用一个 Transformer encoder 状物对每个 token 的位置输出一个 logit 然后最大化被 mask 的 token 处的 ground-truth 的概率 ($\sum\log p$)Problem & Motivation
之前 AR 使用 decoder-only 架构 (causal attn mask), 而 masked diffusion 都使用 encoder-only 架构 (full attn)
这两者架构不同,比较不公平。所以本文提出 decouple [AR/diffusion] 和架构的关系.
也就是说,我们也可以用 encoder + AR (这个本文没管) 或者 decoder + diffusion
Any-Order GPT 等价于 Masked Diffusion
本文提出了 Any-Order GPT 训练方法。也就是,对于所有可能的 permutation,做 AR 式训练.
当然正常的顺序肯定是要给的. 并且好处是,和 diffusion 一样,可以支持任何顺序的生成
虽然听起来很难 work,不过本文 follow 了之前的架构设计 ($\sigma-GPT$), 来融合进 Position information.
当然,比较自然的,这样的训练方法的 loss 可以被证明等价于 Masked Diffusion (当然 practical 肯定是有区别的)。
AO-GPT converges slower than normal AR (废话)
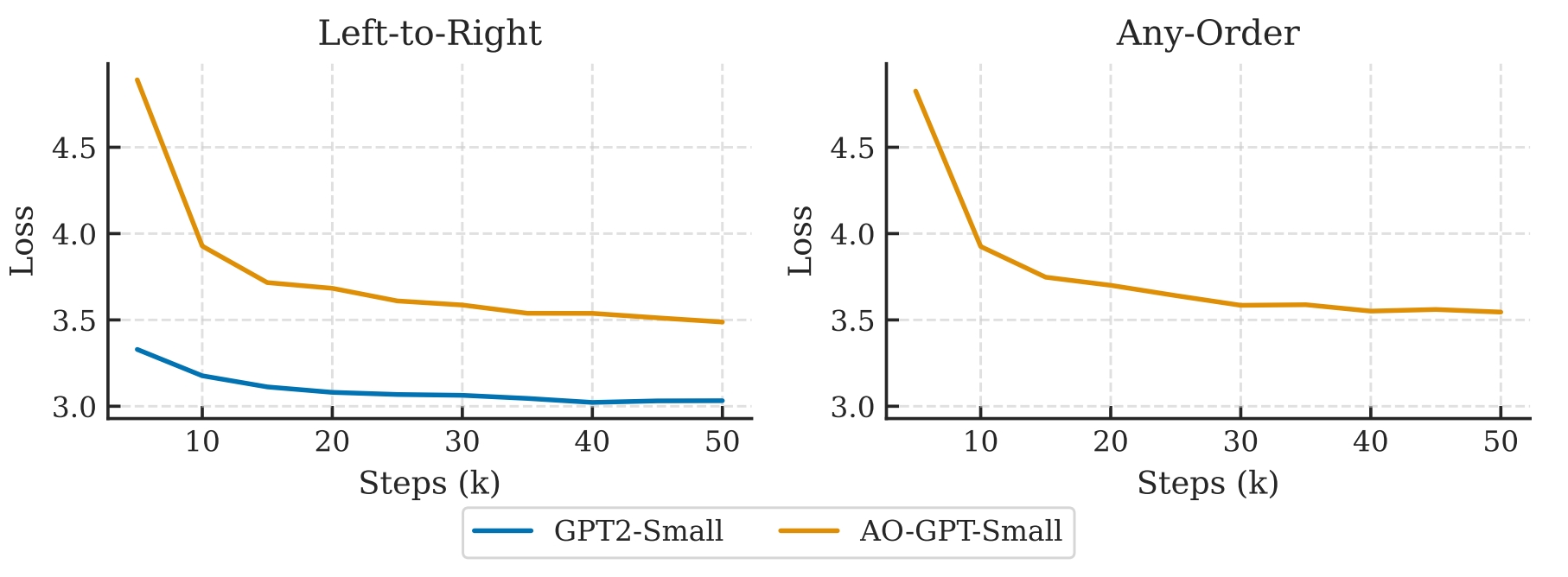
这个 setting 是,训练 AO-GPT 和 AR GPT,然后 eval 他们在 AR 下的 loss,发现 AO-GPT 明显差。
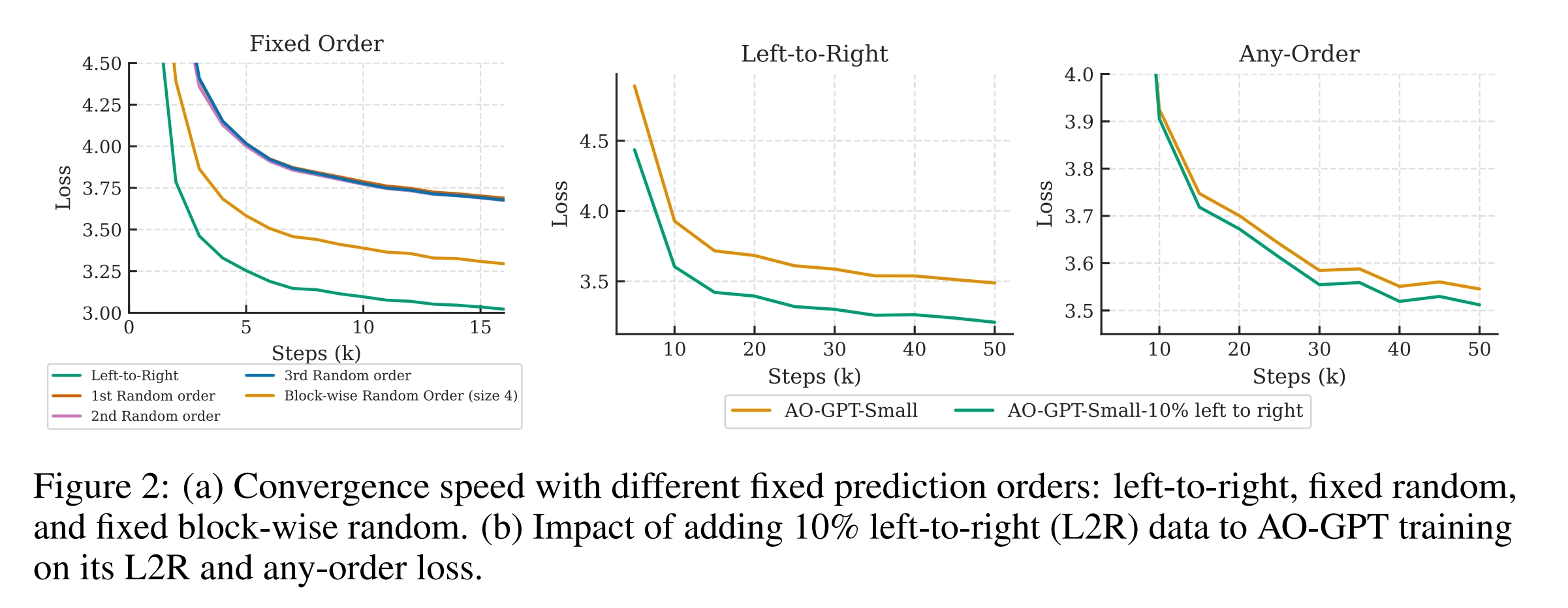
这个 setting 是,作者探究了如果训练的时候只使用固定的 permutation 会怎么样。
比如 random (一开始采定的),block random (对四个一循环,但是这四个的顺序不是 1234)
反正结论是还是 AR 最好。很合理
Trick to make AO-GPT work: Adding 10% AR training data
作者在 training data 中加入了 10% 的 AR. 发现甚至 Any-Order 的效果也更好了
感觉挺合理的,说明加了之后模型终于学会了。加之前 79 能学会。
Difference of Masked Diffusion (encoder) & AO-GPT (decoder)
虽然看上去很等价,但是实际上有不同:
- Encoder-only: Order-invariant
也就是,给定那些没 mask 掉的 token, 剩下每个 (masked 掉的) token 的概率是唯一的,和剩下这些 token 的顺序无关。
但是 AO-GPT 不一样,剩下的 token 不同的顺序会对应不同的概率. 甚至,context (上文) 不同的顺序也会得到不同的概率 (因为有 causal mask)
这件事情就导致了 AO-GPT 需要学的东西更多 ($n!»2^{n}$)
并且实际效果也发现,decoder-only 明显更差。
Technique to Improve AO-GPT: ensemble
作者提出了 ensemble on context order. 也就是,在 (对 permutation $\sigma$) evaluate perplexity 的时候,对每一处 (第 $\sigma(i)$ 个 token),把 context (第 $\sigma(0), \ldots, \sigma(i-1)$ 个 token) 以一个随机顺序打乱来 eval.
然后这样的随机顺序会采多次取平均。这就是 ensemble.
Note: 这样的平均近似了一个 order-invariant prob.
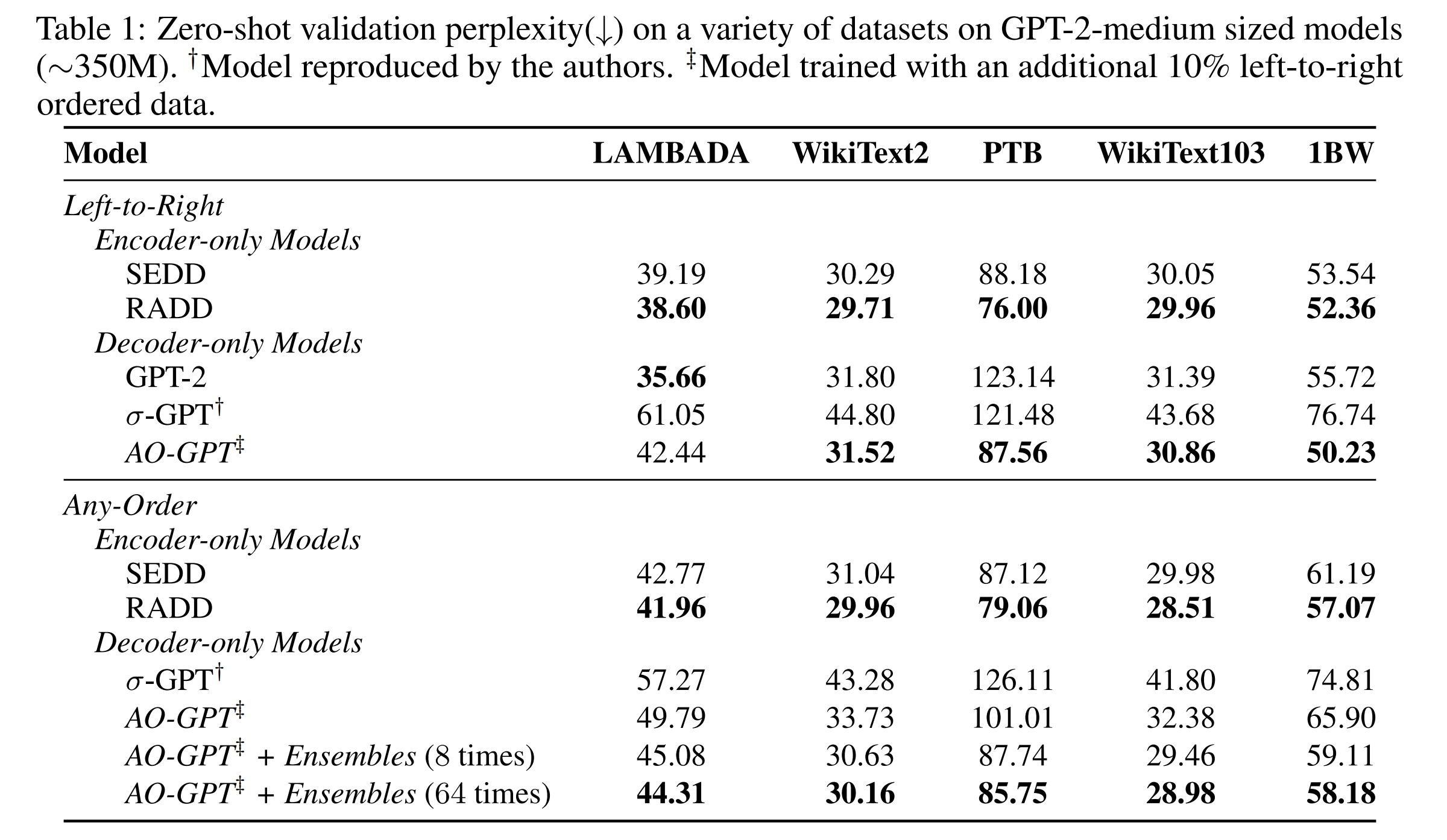
结果如上。ensemble 减小了 encoder / decoder 之间的 gap, 但是还是不如 encoder-only.
这说明 sensitivity to context order 是 AO-GPT 差的主要原因.
Technical Detail: How to inject Position information
这里比较了不同的 position embedding 方法. 因为 AO-GPT 需要更强的 position 信息
下面这一段举例子说明了这一点 ($\sigma-GPT$ 里面提出的也不够好)

作者提出了两种改进:
- 对每个 transformer block 都有一个可学习的 PE.
- 使用 AdaLN 来 encode PE.
效果是 2 > 1 > baseline.
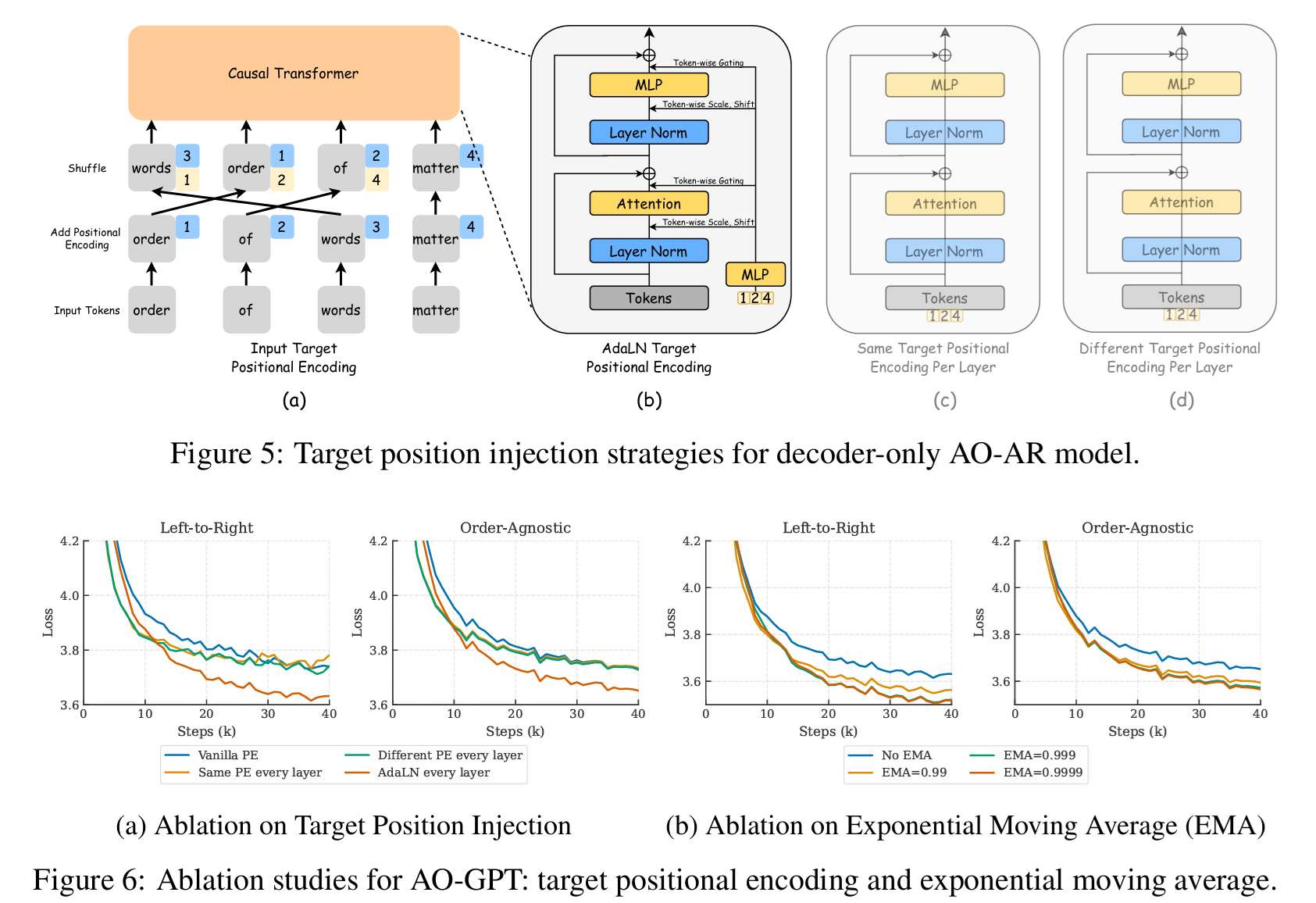
上面这张图里面, 蓝色的数字代表这句话的真实位置, 而黄色应该代表要生成的顺序 (target order)
还采用了 EMA 发现效果更好.