SQA-034
[Paper] Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
本文把小 batch size (甚至 1) 训练做 work 了. 本文的 scope 是 LLM training (对 pretraining / fine-tuning 均适用)
Problem
一般来说小 batch size training 会变得 unstable.
Method
作者发现, 之前我们只对 batch size 调 lr. 实际上 adam 优化器的 beta 也应该调整. 调整过后,training 很稳定,效果很好 (使用相同的数据量)
具体来说,adam 的原理是:
\(m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t\) \(v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2\) update: \(\theta_{t+1} = \theta_t - \eta\frac{m_t}{\sqrt{v_t}+\epsilon}\)
注意到,我们 $\beta$ 也应该调整使得 half-life token 数相同.
Ablations & Results
Optimizer
发现 batch size 越大需要越复杂的 optimizer. batch size 1 的时候,甚至使用 vanilla SGD 就能达到 optimal loss. 这样显著减小了显存开销
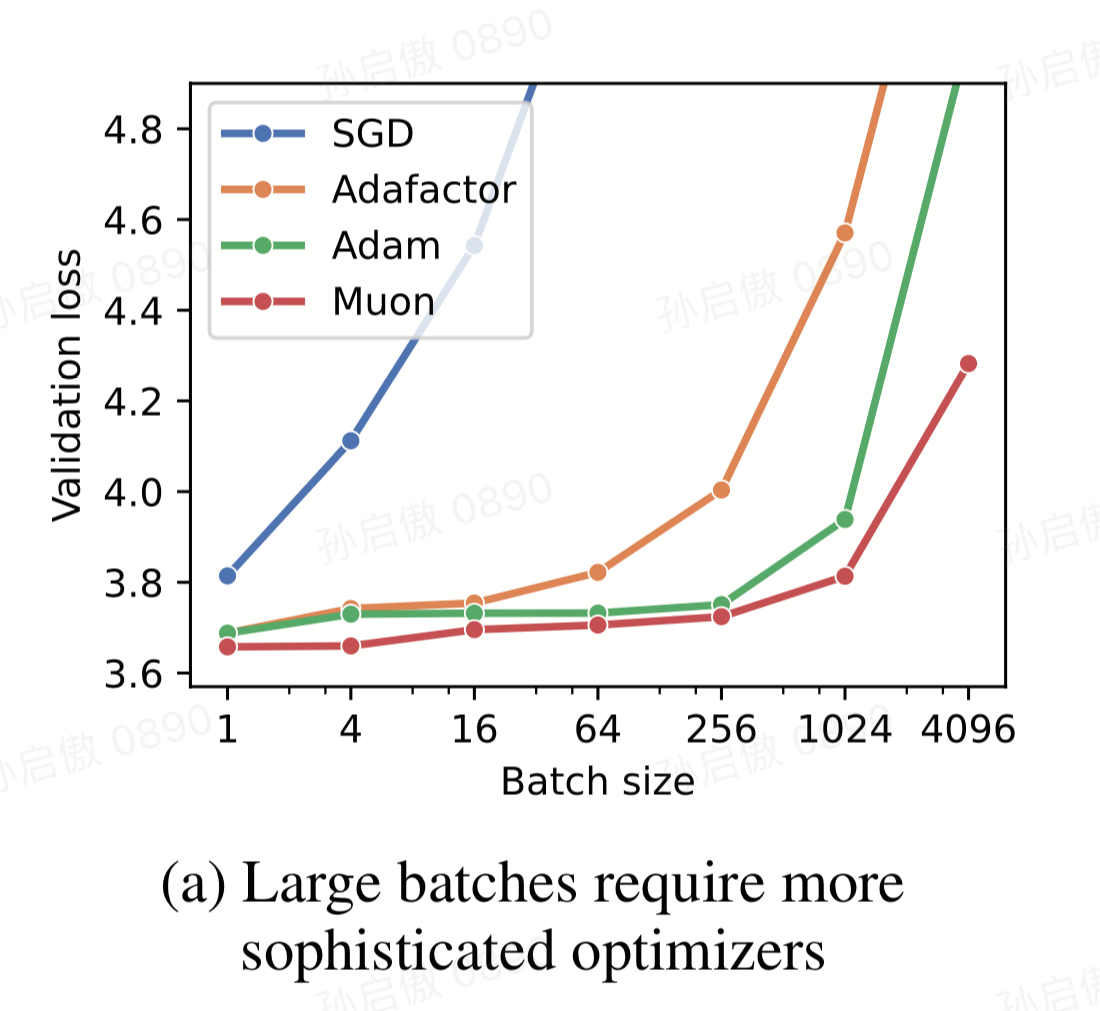
解释:momentum 机制是为了防止 oscillations 的, 但是对于小 batch size 使用的小 step size, oscillation 本身就不容易发生.
大 batch size 的困难点在于估计一个好的大 step size 的方向.
Large Batch size is Sensitive to Hyperparameters
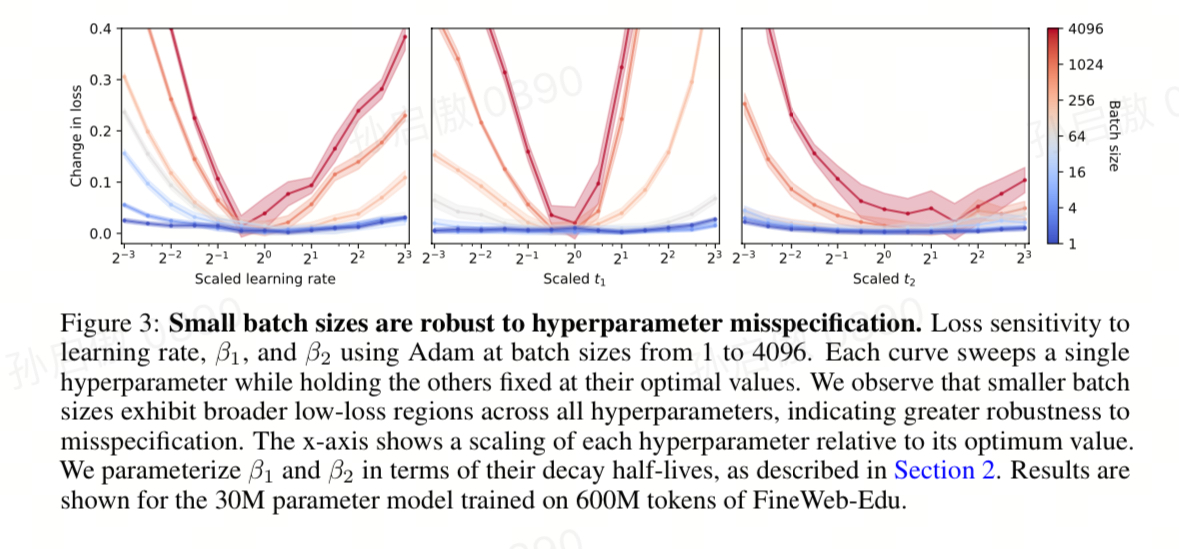
batch size 1 对很大范围的超参都能 work 的很好
$\beta$ scaling
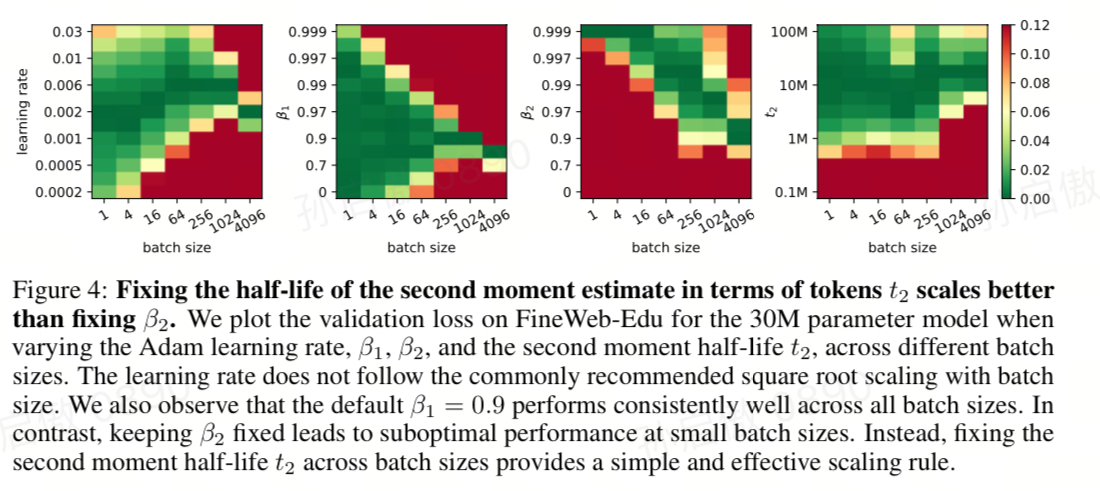
- 对于很小的 batch size,sqrt lr scaling 也不完全对,好像比 sqrt 还要慢很多
- adam $\beta_1$ 可以 fix 在 0.9,效果不错
- 但是 adam $\beta_2$ 需要 scale, 用 halflife
AdamFactor
一个 adam 的省显存版本. 发现小 batch size 用了很不错.