SQA-032
[Paper] FasterDiT: Towards Faster Diffusion Transformers Training without Architecture Modification
这篇文章研究了 SNR 对收敛速度的影响, 以及提出了 velocity direction loss
最终达成了 7x speedup 达成同样的效果
SNR
对于 $x_t=\alpha_t x+\sigma_t\epsilon$, 我们定义的 SNR 定义为 $\dfrac{std^2\alpha_t^2}{\sigma_t^2}$
其中 std 代表数据的标准差.
文中发现这个 std 是重要的, 比如 scale 一下数据集, 那么不同 sampling schedule 的表现会显著不同
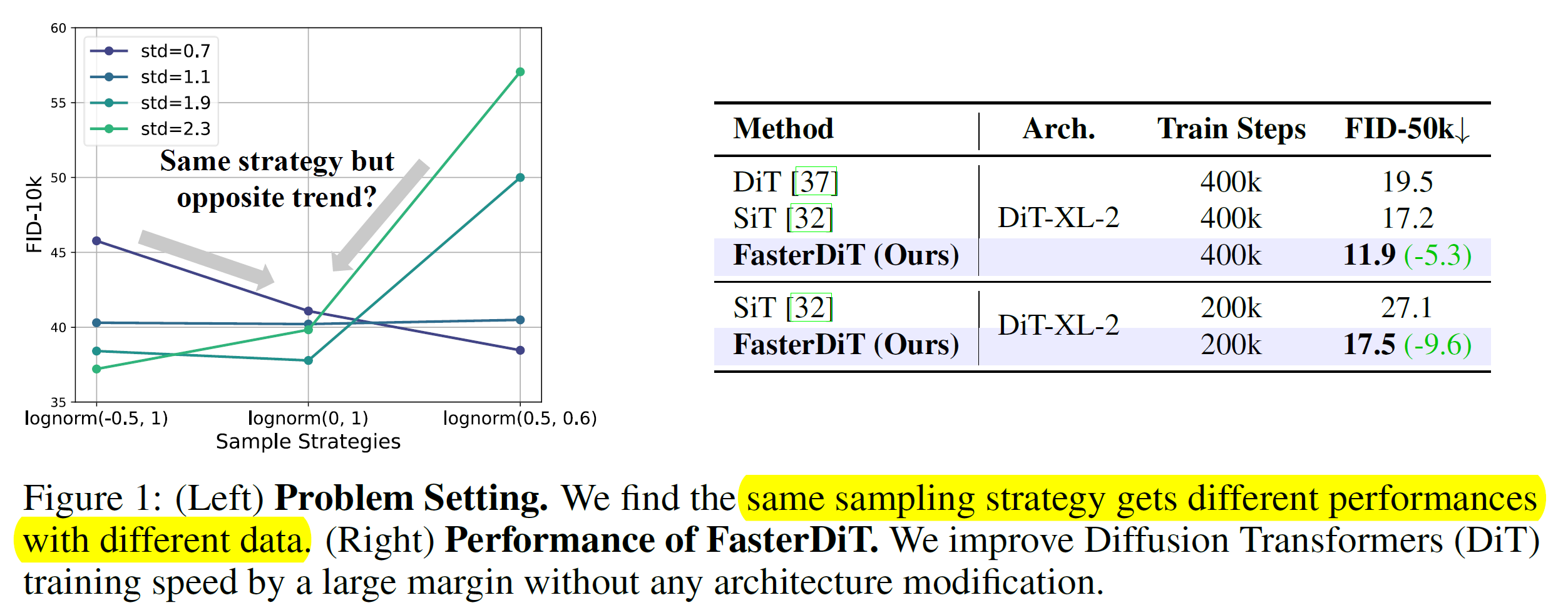
后面推了一堆 79 想看, 总结来说就是考虑 SNR 的分布 (这个分布和 t sampling schedule 有关)
- 对于不同 std, 最优 SNR 的分布类似
- SNR 的分布需要有 focus, 并且这个 focus 要对
Velocity Direction Loss
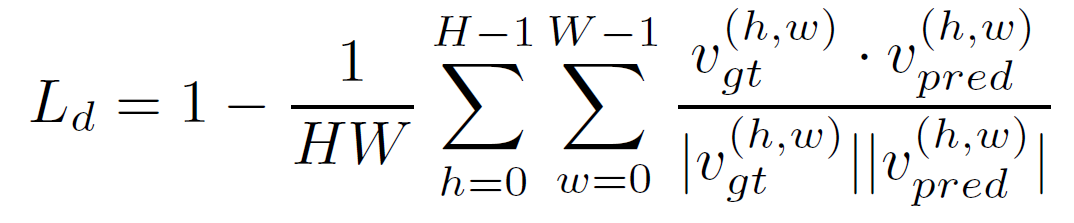
同时 apply MSE 和这个 loss, 能显著提升效果