SQA-030
[Paper] Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
这篇工作主要提出了一个新的 loss 来训练 latent diffusion 的 VAE (叫做 VA-VAE, Vision foundation model Aligned VAE).
Problem
目前的 VAE 面临一个 dilemma: 如果使用的 latent dim 太小, reconstruct 不好; 如果使用的太大, 那么不利于 diffusion 在上面训练, 收敛会非常慢, 通常需要很大的模型才能做.
其根本原因在于维度高的时候是一个高度 unconstrained 的优化问题, 导致 VAE 学出来的东西意义不好
这个问题有些类似 VQVAE 中, 如果 codebook 太大那么 codebook utilization 会很低
Method
VF loss
作者想到借助预训练的 representation 来引导 VAE 的训练.
之前的工作做过, 直接拿预训练的 feature model 作为 encoder 的初始化, 但是效果并不好.
所以引入了新的 VF loss: 对于模型生成的 latent $Z$ 和 feature $F$, 先用一个 linear 把 latent 映射到 feature 的维度 $Z’=WZ$
然后我们有两项 loss: cosine similarity loss & distance matrix loss (这看起来有点唐)
我的理解是需要我们的 feature 的维度还是 $h\times w\times c$ 的样子
\[\mathcal{L}_{mcos} = \frac{1}{h\times w}\sum_{i=1}^{h}\sum_{j=1}^{w} \text{Relu}\left(1-m_1-\frac{z_{ij}'\cdot f_{ij}}{\|z_{ij}'\|\|f_{ij}\|}\right)\]这个 loss 是 spatial 上面的 cosine similarity
其中 $m_1$ 是一个 margin, 也就是只对于不太像的地方有梯度
除了这个, 还有下面这个 loss, 没太看懂, 反正是总归
\[\mathcal{L}_{mdms} = \frac{1}{N^2}\sum_{i, j} \text{Relu}\left(\left|\frac{z_i\cdot z_j}{\|z_i\|\|z_j\|}-\frac{f_i\cdot f_j}{\|f_i\|\|f_j\|}\right|-m_2\right)\]感觉不玄学
不过后面的 ablation 说都是可以 work 的
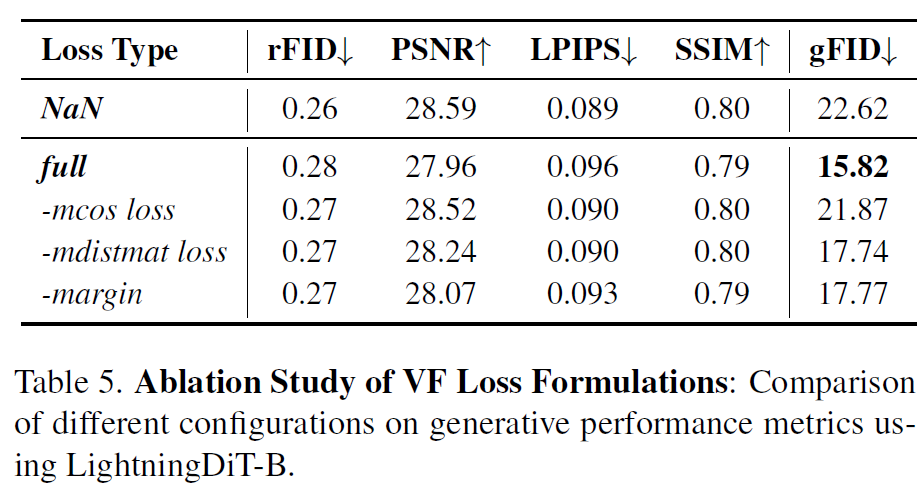
training technique
懒得看, 用了一个有意思的 adaptive weighting
Improved DiT
这篇文章还把 DiT 改进了很多, 叫做 LightningDiT
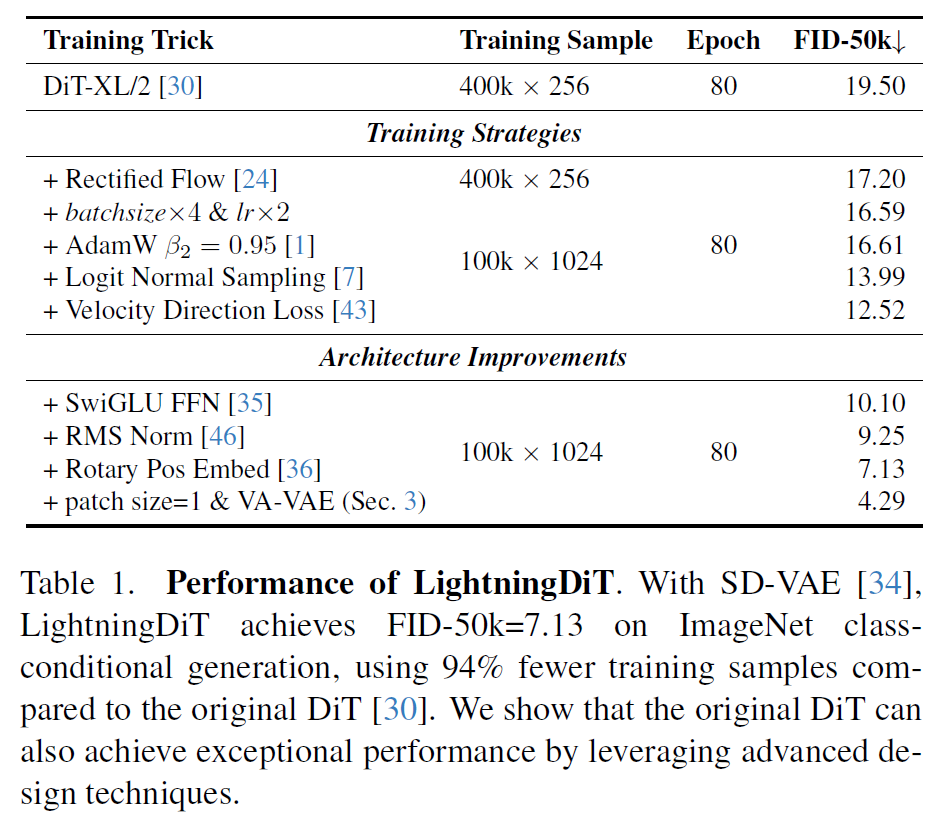
- 改成 SiT
- batch size 加到 1024
- logit norm sampling
- Velocity Direction loss (这个我还没看是啥)
- 架构上的改进: FFN, RMS Norm, RoPE
这个调的弱.
对于最终大结果的训练, 在 480 ep 的时候 disable lognorm sample, 改成 uniform, 让接近收敛的模型对各个时间步骤都学
还使用了 cfg interval 和 timestep shift
Result
利用改进的 DiT, 使用 downsample 16 倍的 VAE 以及 patch size 1 来训练
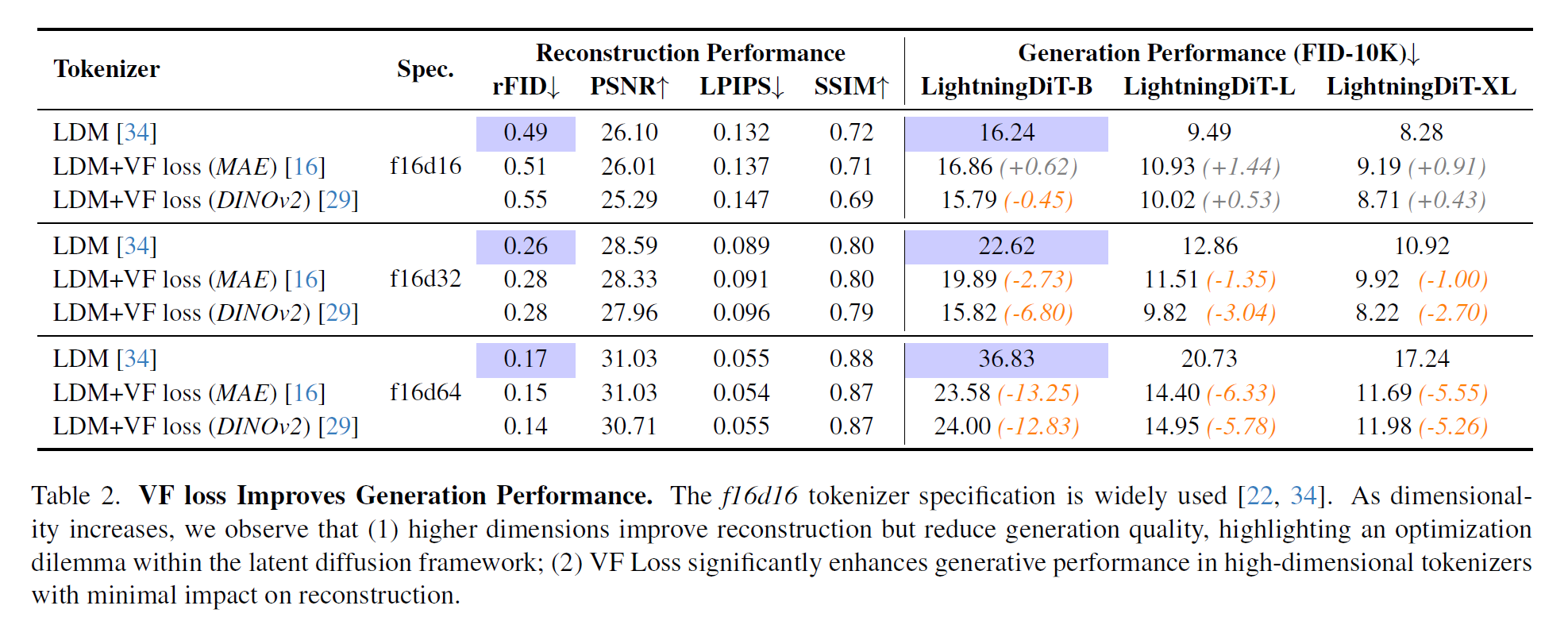
结论: 提出的 VA-VAE 对于 dim 比较大的时候能帮助 DiT 收敛变快以及效果变好, 不过对于 dim 小的时候并没有用
对于 representation model, 使用 DINOv2 最好