SQA-027
[Paper] Transformers without Normalization
本文主要说明了神经网络里面的 normalization 层是可以被简单的激活函数 tanh 替换的.
Method (TLDR)
把 LayerNorm 可以换成 Dynamic Tanh:
\[DyT(x) = \gamma * \tanh(\alpha*x) + \beta\]其中, $\alpha$ 是一个 learnable scalar (形状为 1).
Initialization
Default 把 $\alpha$ 初始化为 0.5. $\beta, \gamma$ 用 trivial initialization.
后面 ablation 说 $\alpha$ 大概到 0.6 就有可能爆. 对于 LLM 来说, 越小初始化越稳定.
Motivation
动机是发现 LayerNorm 的 mapping 很像 tanh 的形状.
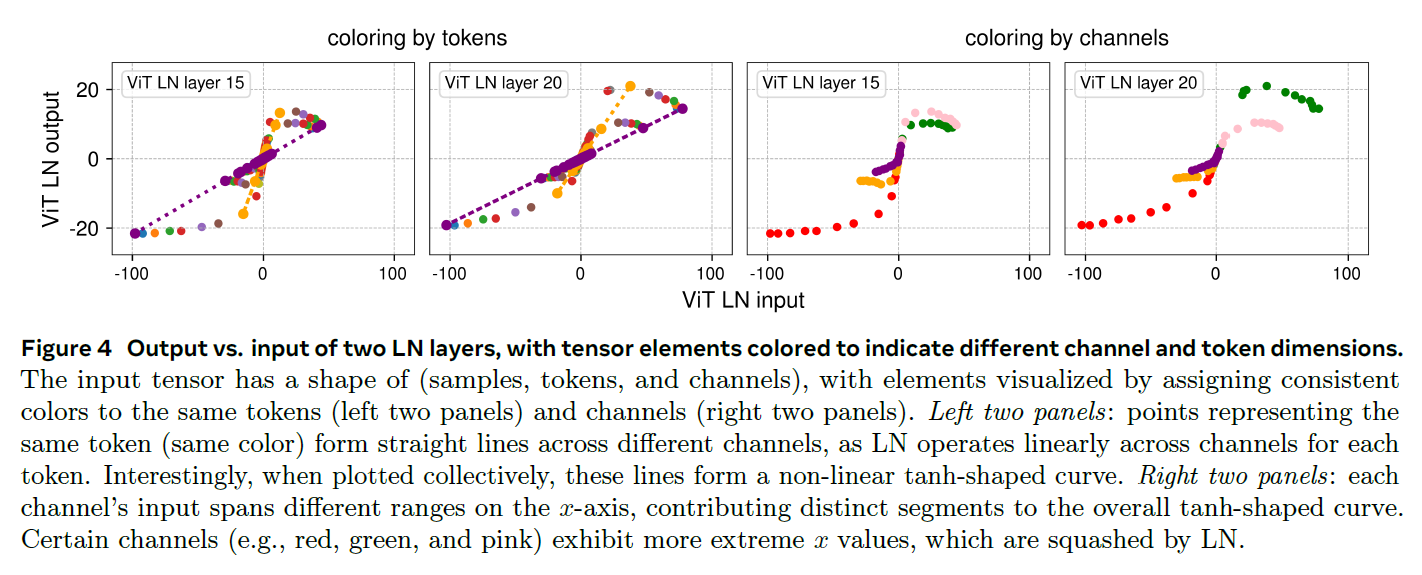
反正 Norm 层的本质用处就是 把极端值用一个 non-linear 的方式去掉并且几乎保持中间的部分近似线性.
Results
做了各个领域的实验, 发现基本不掉点还能涨 (基本不调参). 还挺 robust 的.