SQA-023
[Paper] JetFormer: An Autoregressive Generative Model Of Raw Images And Text
很有意思的工作! 在大模型时代还使用 Normalizing Flow 来作为图片的 tokenizer, 非常创新. 和 Normalizing Flow 的关系相当大!
Problem
之前大部分的 Image Encoder 都需要 pretrained VAE or VQVAE, 这样的做法可能会导致信息损失.
这个工作实现了完全 End-to-End 的 Text2Image 生成模型, 直接从原始图片和 text 中学习.
Method
具体来说, 使用一个 Normalizing Flow 来作为 tokenizer, 把图片变成 soft-tokens (也就是连续的 token).
最后使用一个 decoder only 的 transformer 来 model 这些 token 和文字的 token 的分布.
其中, token 的分布直接由输出的 softmax 得到, 而 image soft token 的分布是由 decoder 输出作为 GMM 的参数来 model. 这个非常巧妙! 好像是借鉴了 GIVT 的做法.
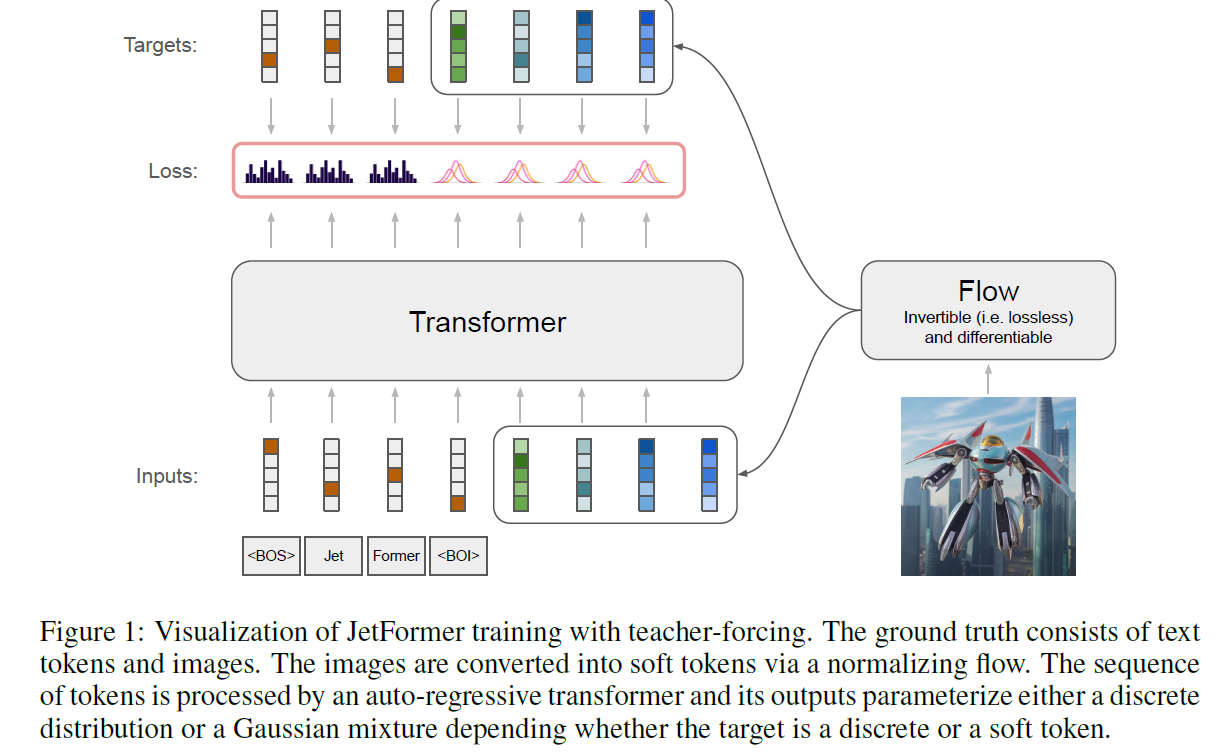
值得注意的是, 这个 Normalizing Flow 是完全 lossless 的. 并且训练的时候二者是联合训练的.
(事实上, 这里还作了个弊. 往后看会发现, 这里的 NF 并不是完全 lossless 的)
并且 encode image 和 generate image 的 token space 是同一个. 也就是说 NF 同时帮助 understand 和 generate.
整个训练过程完全只有 NLL loss.
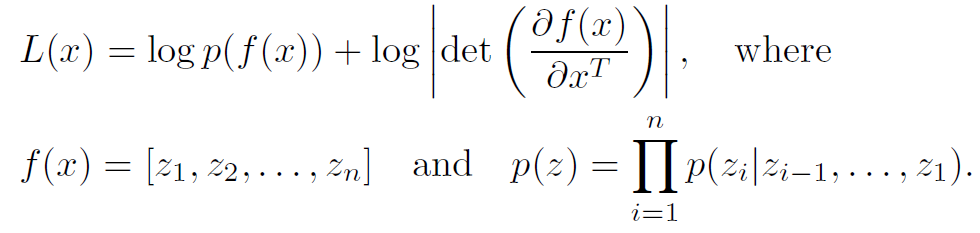
这里 $p$ 是 decoder 所代表的 GMM 分布.
缺点 (Personal)
Normalizing Flow 的架构限制是一个很大的问题.
同时 NF 必须保持维度不变.
Tricks to train NF
首先, 为了保证连续的分布, 对 0-255 的图片像素进行随机连续化 $x=I+u, u\sim U[0,1]$ (dequantization).
sample 的时候使用 CFG. 具体做法不太清楚, 好像是在 GMM 上面做一些 rejection sampling 之类的. 见 GIVT.
Factoring out redundant dimensions
这里的想法是, 图片的信息是十分冗余的. 那么, 我们的 latent token 其实并不需要这么多的 channels.
但是 NF 必须保持维度相等, 怎么办呢?
非常聪明的想法: 我们把 latent space 中的 channels 分成两部分, 前一部分用 decoder GMM 来 model, 后一部分直接用 Gaussian 来 model.
具体来说:
- Training: 把图片 $x$ 经过 NF 之后, 前一半 channel 使用 decoder GMM loss, 后一半使用 Gaussian loss.
- Sampling: 用 decoder 来 sample 前一半的 channels, 然后剩下的 channels 直接用 Gaussian 来 sample. 最后通过 NF reverse 来得到图片.
所以我们的 decoder 只需要 model 一个更小的 channel 数量.
这样看上去也是非常好的 representation! 虽然文章中没有 evaluate 这个 representation 有多好.
Ablations on low-dim
相对于上面的方法做降低维度的事情, 文中还对照了另外两个方法:
-
在 patchify 之后, 拍一个 invertible 的 learnable linear projection $W$. 然后我们只取 $xW^T$ 的前 $d$ 个维度, 用 NF 来 model. 并且 sample 的时候直接把剩下的用 Gaussian 来 sample. 注意, 这个 setting 中 loss function 中还要加上 $W$ 的 Jacobian.
-
把上述的 $W$ 换成 frozen 的 PCA 变换.
Noise curriculum
注意到 NF 直接训练会很难关注全局结构.
所以选择的做法是, 对数据加噪声, 然后这个噪声从大变小.
这样一开始模型看到的有噪声的图片就会关注到全局结构.
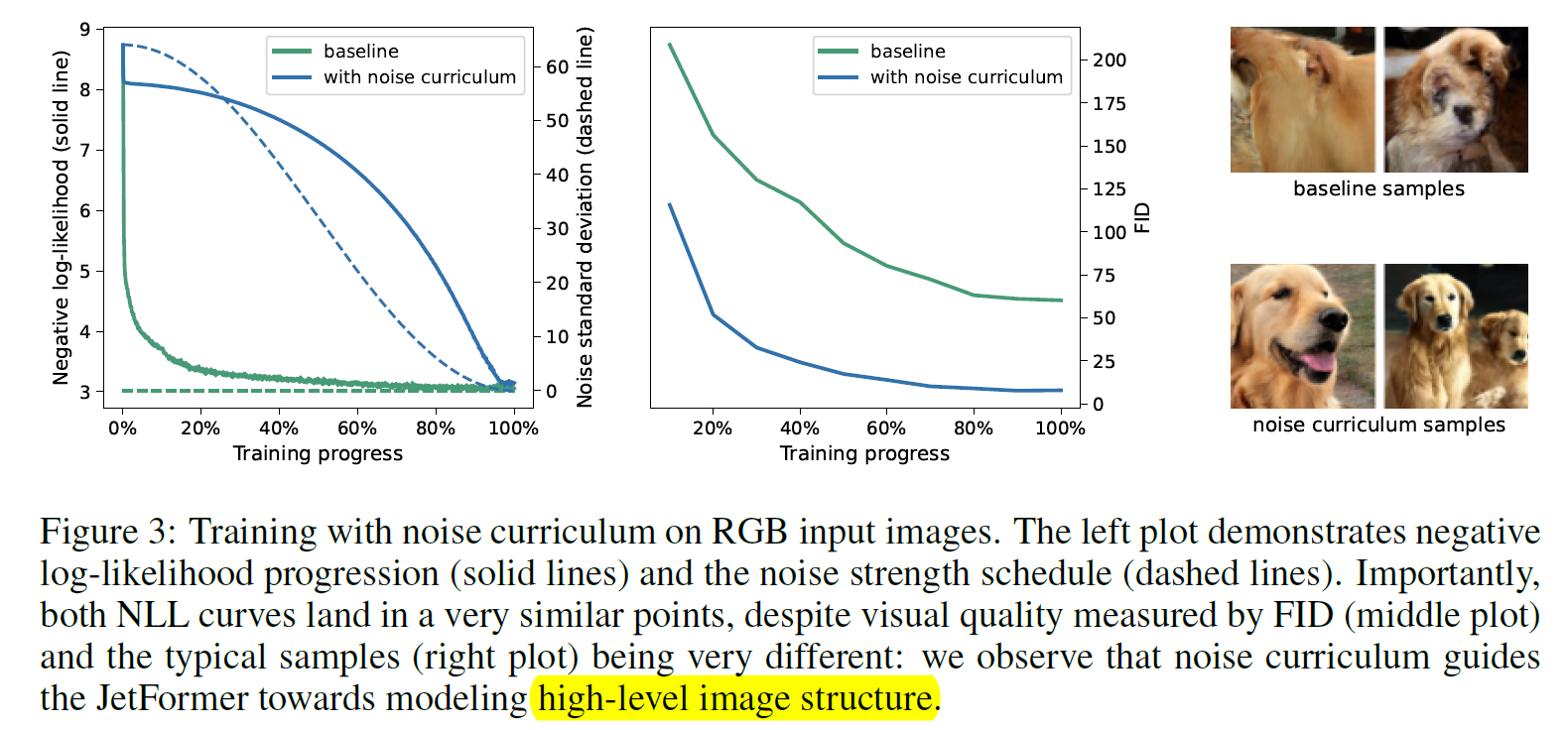
具体做法是, 最大的 noise level 在 0-255 pixel 上面是 64. 可以发现还挺大的, 基本相当于 0.25.
最后 cosine decay, 对 ImageNet 降至 0, multimodal 降至 3.
Setting
训练使用 ImageNet 以及 text-image pairs.
其中 text-image pairs 要么是先 text 后 image, 要么是先 image 后 text.
其中的细节是, 训练的时候希望对前一半 (modality) 的输出 freeze 住, 只对后一半做 loss. 这个是比较合理的, 因为我们更关心 condition generation.
NLL loss 中 text 的 loss 相比图片乘了一个 weight 0.0025. 这个是为了让两个 NLL 的 scale 一致.
Model architecture
这里使用了另一篇 Jetformer 的架构, 主体是 transformer-based coupling affine layer.
其中的 split 是沿着 channel 维度进行的. 因为发现 spatial split 的效果不好.
对于 256x256 的图片, 使用巨大的 16x16 patch size, 然后对于 factor out 的维度只取 $3\cdot 16^2=768$ 中的 128 维.
Transformer decoder 使用了经典的 Gemma 架构 (虽然我不熟悉, 是 google mind 的).
GMM 预测的 mixtures 有 1024 个.
对于 ImageNet 这种 class-conditional, 我们选择使用 16 个前缀可学习的 token 来代表 class.
Results
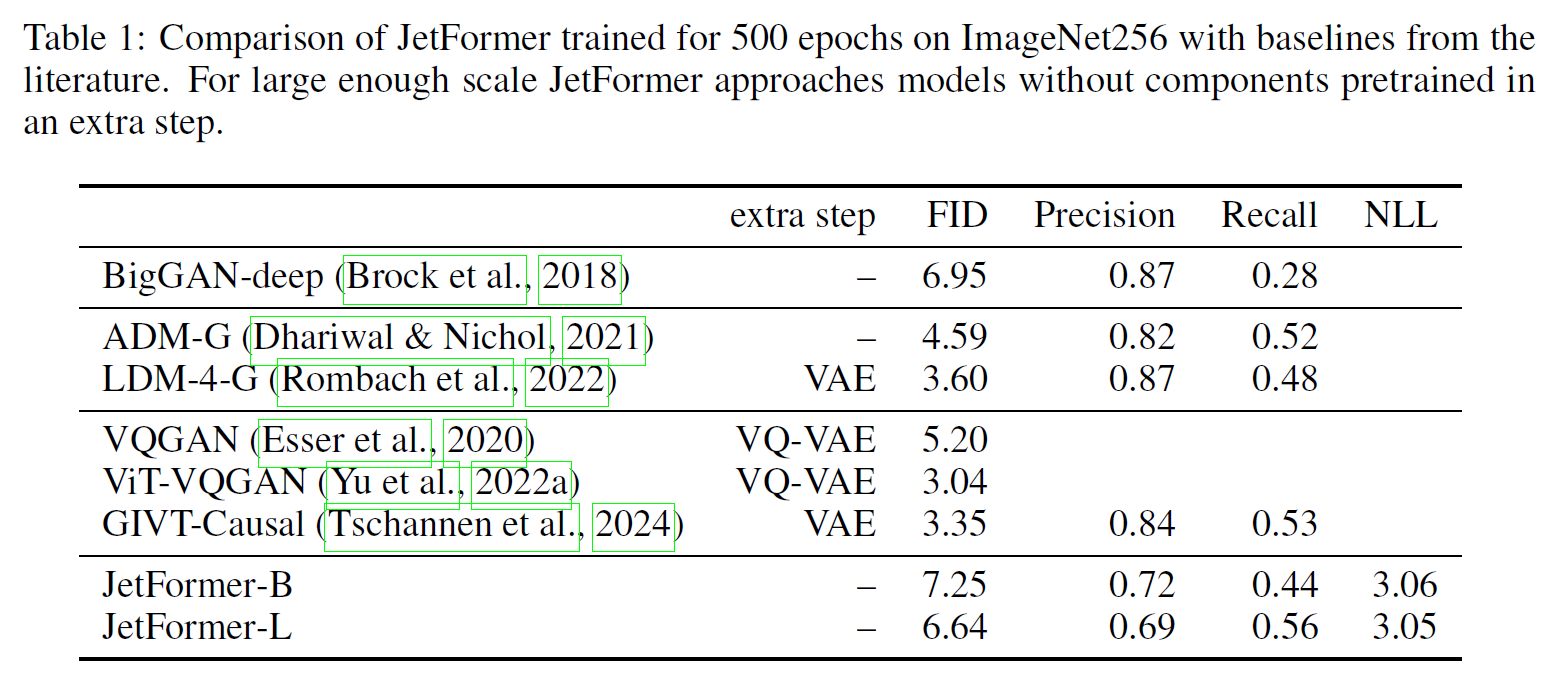
这里显示了 imagenet 的结果. FID 还挺好看的, 模型也应该挺大的. 注意这里面 Recall 尤其地好, 也许是因为显示的 log prob.
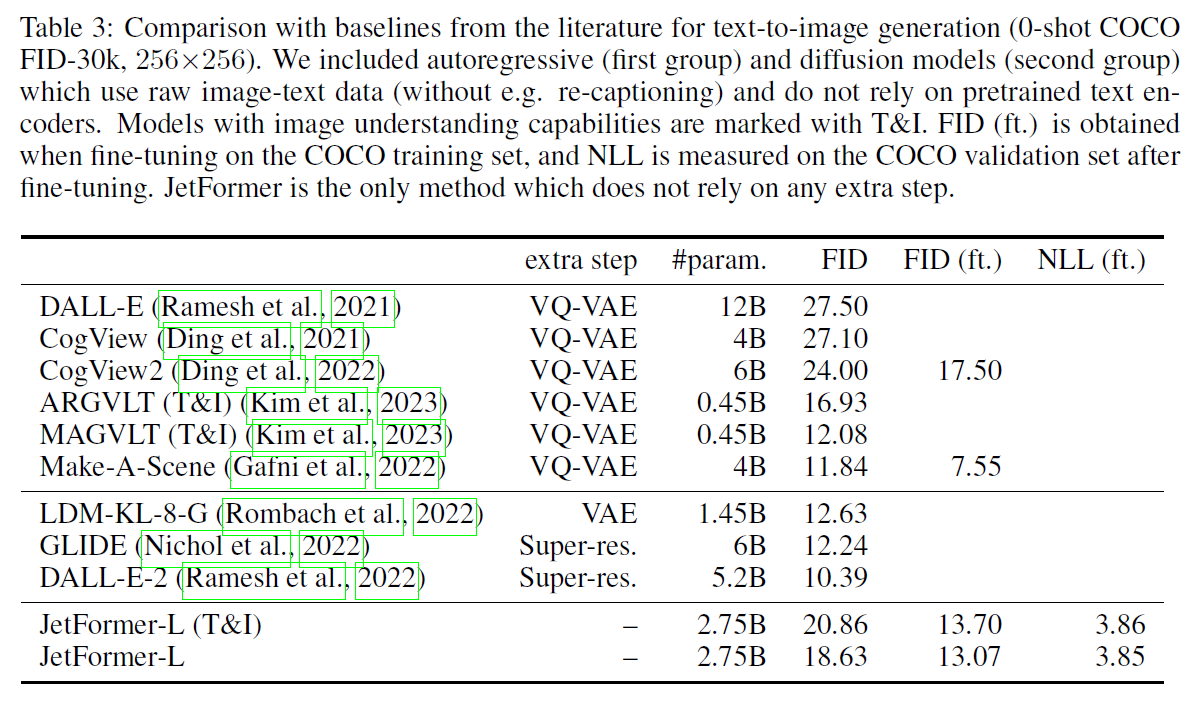
这里是和牛鬼蛇神打. 基本还是能打过不少的.
还做了一些 zero-shot 之类的实验, 懒得看
Ablations
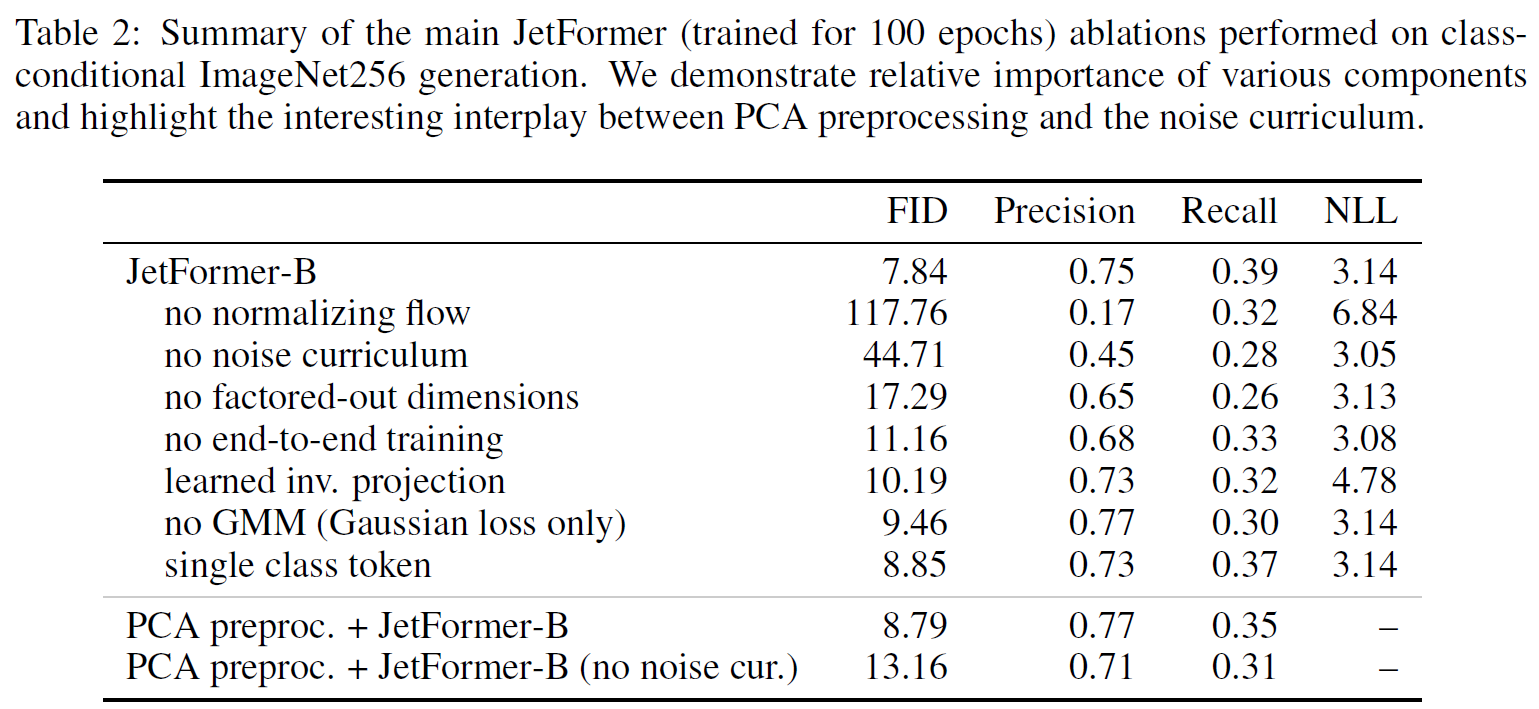
这个 ablations 做得很好!
- 如果没有 noise, 会显著变差.
- 甚至没有 factor-out dim (也就是直接对 768 channels 做 decoder model), 效果会变差不少! 很吊
- 以及 end-to-end 会更好. 这个挺合理的
- 如果使用之前提到的 learned inverse projection 的 setting, 只会变差一点点. 高潮了
- 使用 PCA 有类似的结果.
- 如果把 GMM 置换成单一的 single Gaussian prediction, 效果只会变差一点点.
- 在 ImageNet 上面如果只使用一个前缀 class token, 效果会差一点点. 真是不择手段
- 有趣的是, 如果使用 PCA, 那么没有 noise curriculum 反而 degrade 得比较少.
Appendix
文中提到, dropout 对 sample quality 有显著影响.

这个图片展示了各种情况下的类似 “reconstruction” 效果.
其中, a 为原图, b 为加噪图片
c 为对着图片过了 NF 之后的 latent 中, 只保留前一半 channels, 后面一半用 Gaussian resample, 然后重新流回去的结果. 这个结果相当有意思, 说明模型学到了把重要的东西全部放到这些 channels 中. 不过, 在后面两张图片中能清晰地发现 patch 之间的不连续.
d 为上面说的 learnable inversible projection 的结果, e 是 PCA setting. 这个发现的结果和 c 类似. 总之说明图片的真实维度真的很低! 比较有意思的是它们甚至能很好地还原出文字.
f 为使用 VAE reconstruction 的结果, 可以明显看出来在细节处理上差不少不过图片总体质量不错. 但是像处理这种文字什么的就不太行.