SQA-022
[Paper] CLIP: Learning Transferable Visual Models From Natural Language Supervision
OpenAI 的大作: CLIP (Contrastive Language-Image Pretraining). 只能说很牛逼
不过论文里面废话有点多, 真的巨长…
Problem
原来使用 text supervision 做 image representation learning 的方法一般是先用 visual encoder 来提取出 representation, 然后喂进 language model 作为 condition 来训练一个概率模型.
老方法在 ImageNet zero-shot 分类只有 11% 的准确率, 非常垃.
Preliminary: dataset
OpenAI 自己搭了一个 dataset WIT (WebImageText), 400M image-text pairs. 人
Method
想法很简单, 类似 CV 中的 contrastive learning.
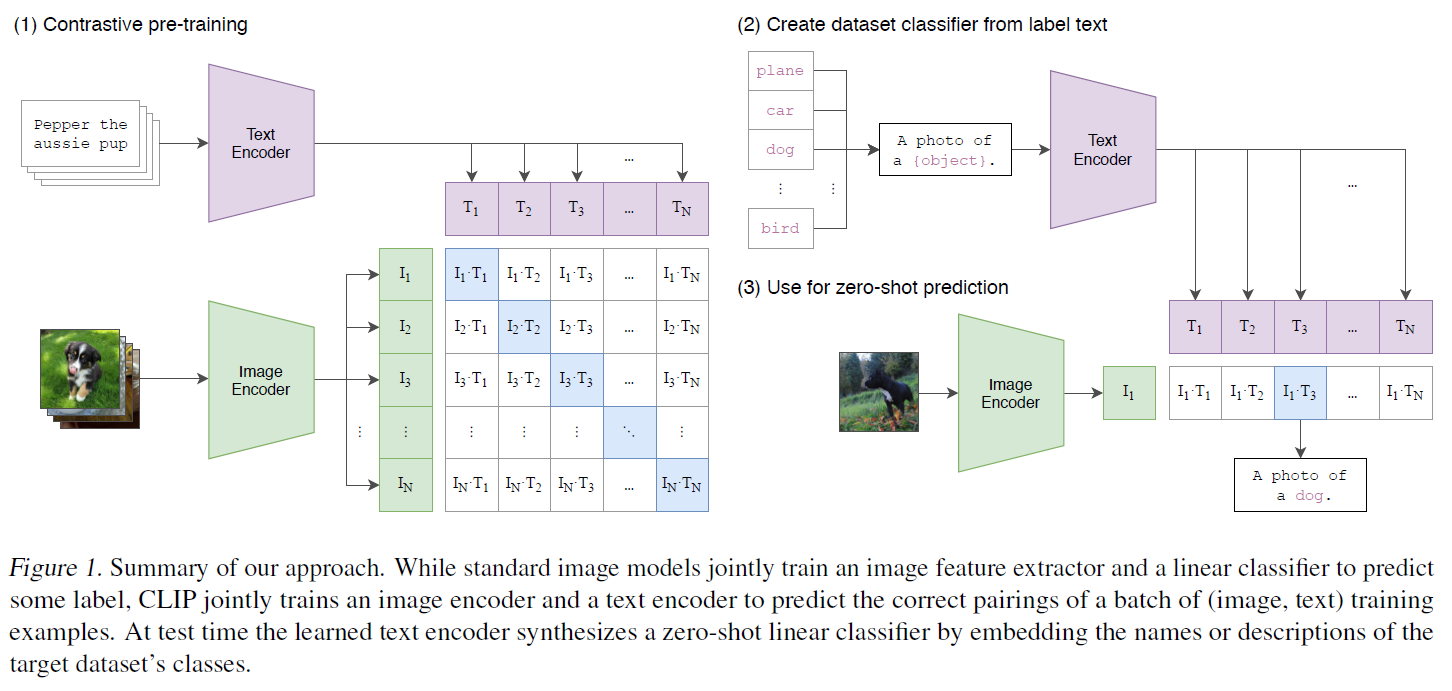
就是直接把 text embedding 和 image embedding 做 contrastive learning, 用 InfoNCE loss 来训练.
Contrastive Learning is more efficient!
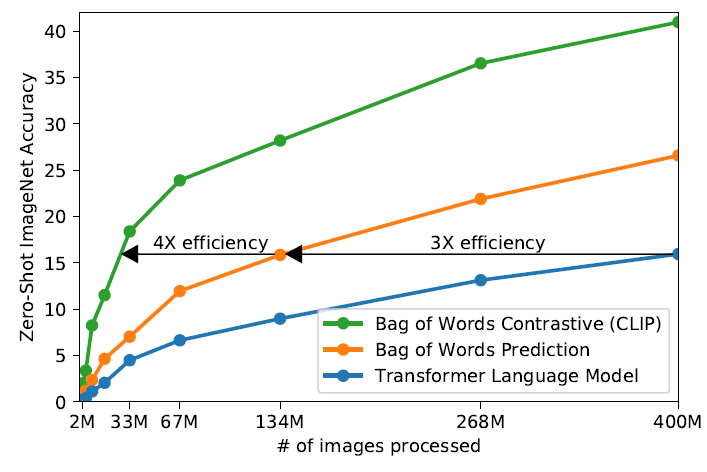
这里我们看到, 老东西的问题是, 就算 text model 的 transformer 很大, 但是学得很慢. 甚至 Bag-of-words 的 baseline 都比他快.
- 这里的 BOW 指的是给定 image representation, 直接预测每个 word 是否出现的概率.
而 contrastive learning 能让这个再快三倍!
Details
注意这里数据集很牛, 所以基本不用担心过拟合.
在 vision & text encoder 之后, 有一个 linear projection layer, 把两个 encoder 的输出都投影到同一个空间 (multi-model space).
没有像 SimCLR 里面的 MLP projection head, 只是线性.
里面的 temperature 使用可学习的 (parameterize: exp). 这个很有意思
- 但是后面说了学的时候得 clip, 并且是很重要的技巧. 唐
Architecture
Vision encoder 选用魔改过的 ResNet 和小改的 ViT.
ResNet 里面改的有点多, 好像 global average pooling 后还加了 attention. 弱的
不过 ViT 还是牛, 好像效果比 ResNet 好.
Evaluation
Zero-shot classification
ImageNet 上直接分类能到 70+, 吊打 baseline.
发现 prompt engineering 可以提 5 个点. 巨唐
eval 的数据集少…
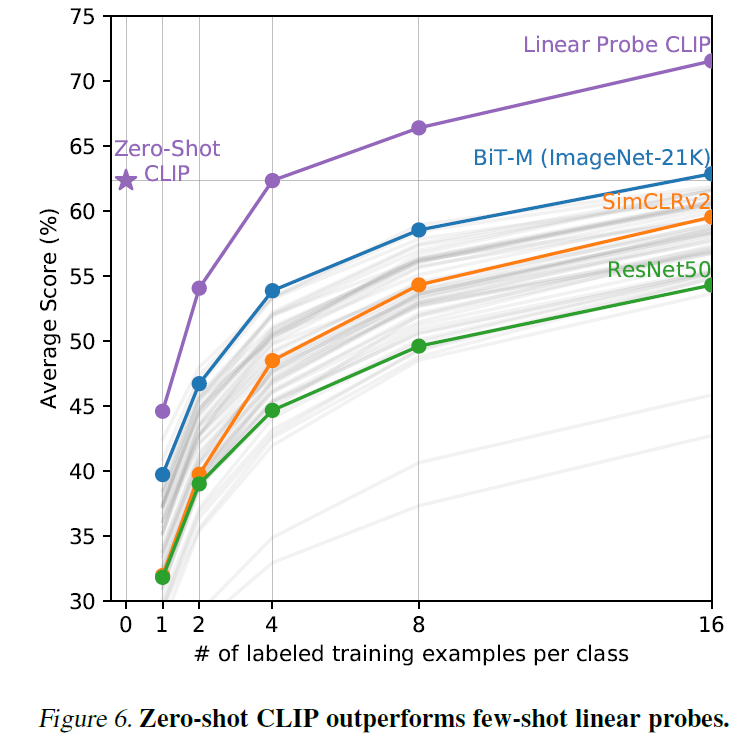
这个弱爆了, 吊锤 SimCLRv2 等. 不过这里感觉有点作弊, 因为数据集很牛, 并且 eval 了一堆数据集取平均.
Linear Probe
懒得看, 反正很牛
CLIP is more robust to distribution shift
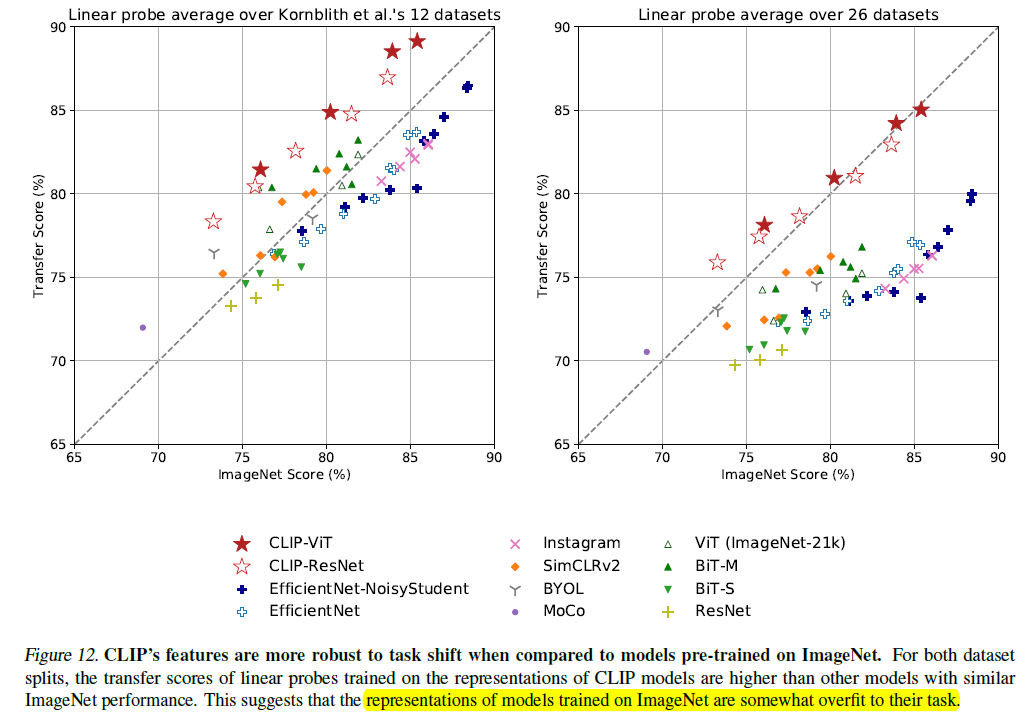
反正就是说在 ImageNet 上训的比较难应用到别的数据集上. 嘲笑