SQA-020
[Paper] PixelFlow: Pixel-Space Generative Models with Flow
这篇论文就是在 pixel space 上做 Flow Matching, 做法类似 VAR
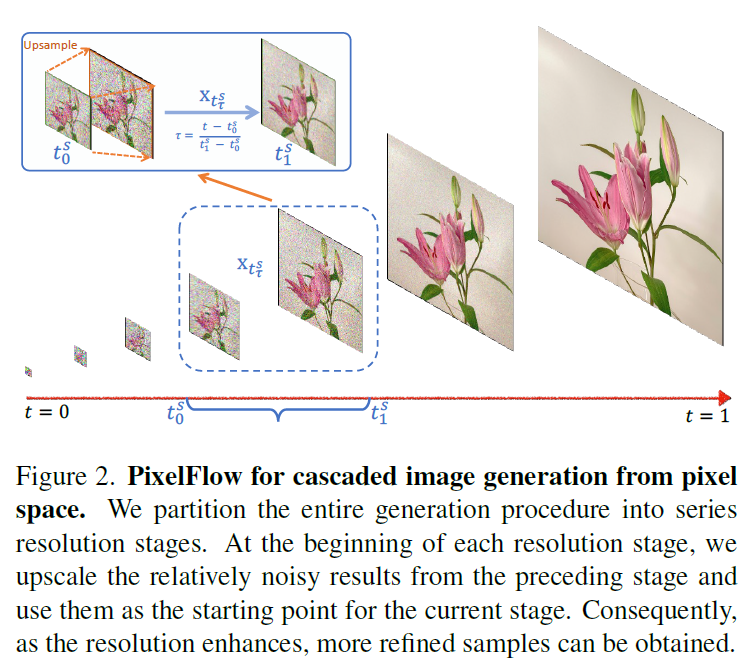
简单来说就是在 Flow Matcing 的去噪过程中加几个 Upsample 的过程, 不过使用同一个网络处理不同的 resolution
Method
分成 $S$ 个 stage. 第 $s$ 个 stage 假设对应的 timestep 是 $t_0^s\rightarrow t_1^s$. 那么训练的两端是:
start:
\[x_{t_0^s}=t_0^s\cdot \text{Up}(\text{Down}(x_1, 2^{s+1}))+(1-t_0^s)\cdot \epsilon\]end:
\[x_{t_1^s}=t_1^s\cdot \text{Down}(x_2, 2^{s})+(1-t_1^s)\cdot \epsilon\]注意这里先 Down 再 Up 是有误差的.
然后在每个 stage 里面我们把这个看作 0 $\rightarrow 1$ (也就是 rescaled timestep $\tau=\frac{t-t_0^s}{t_1^s-t_0^s}$), 用 FM 的方法来做.
Model architecture
模型采用 DiT-XL.
Embedding
为了应对不同的 resolution, embedding 改成了 2D-RoPE.
同时还加了一个额外的 resolution embedding.
T2I
对于 Text-to-Image 的任务, 架构采用 DiT 里面的 cross-attention.
Details & Tricks
Configuration
sample 的时候使用 Euler 或者 Dopri5 solver (79 知道是什么).
使用了 renoising strategy. 我猜大概是 upsammple 的时候 noise 的变化, 这个是合理的.
实验数据是 ImageNet-256 和 T2I 1024x1024.
Ablation: kickoff image resolution
就是从什么 resolution 开始做
实验了 target 64x64 的时候, 从 8x8 开始会比 2x2 或者 32x32 好. (但是 FID 区别好像并不是很大)
所以看起来做 VAR 状物是有道理的 (虽然我觉得不一定能 apply 到大 resolution 上).
Ablation: patch size
发现 4x4 最好. 注意这里对不同的 resolution 的 patch size 是一样的.
Inference schedule
论文的方法是每个 stage 做 30 步. 实际上可以不同的 stage 用不同的步数, 但是作者可能懒得调了.
CFG 的 schedule 对不同的 stage 不一样, 分别是 0, 1/6, 2/3, 1 (0 对应 no CFG). 这个可以涨点 (2.43 $\rightarrow 1.98$).
总之还挺厉害的, 在 pixel level 上 work 得不错, 而且效果比 SiT 还好一点点, 离 SOTA 还有点距离. 不过缺点还是在最高的 resolution 上还是很慢.