JZC-009
[Paper] Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models
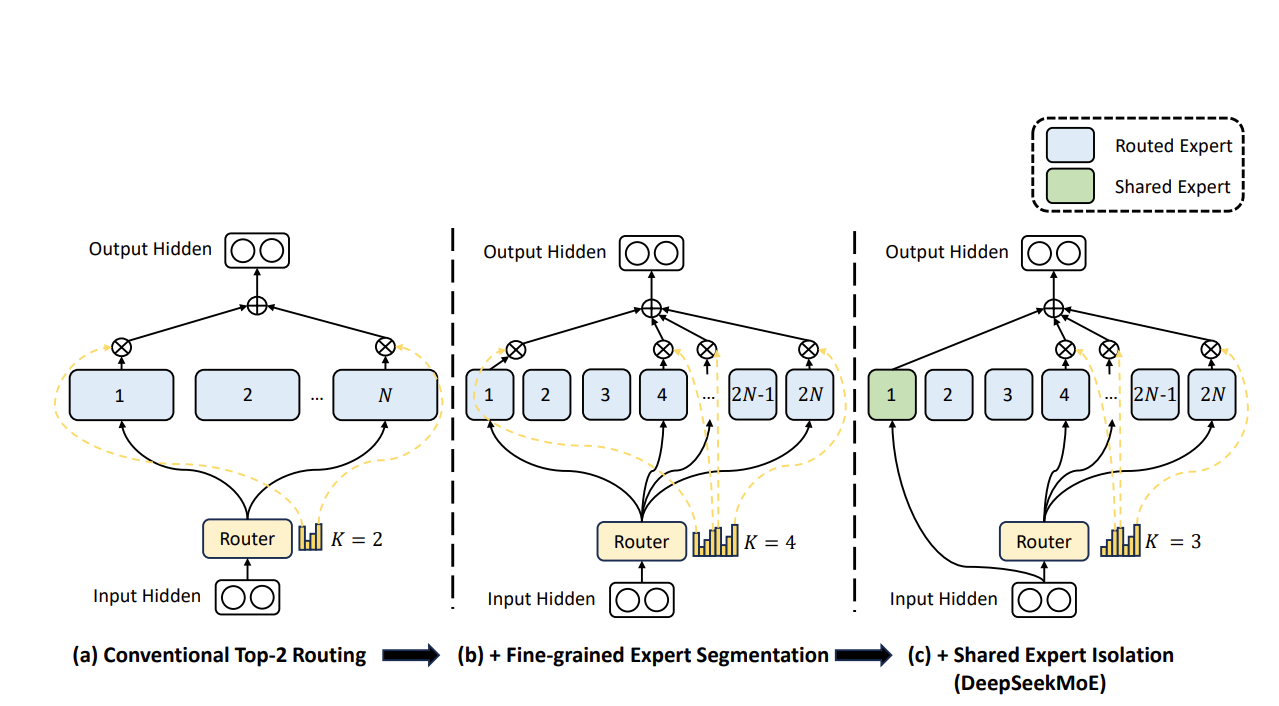
这篇文章提出了一种新的MoE架构。相比于传统的MoE,主要区别在于两点:(1)一般的MoE不改变latent维度,而它提出了fine-grained expert,把$d$维的latent切成若干更小的块,每个块进行MoE. (2)提出shared expert,即一些expert可以被多个task共享,剩下的由routing network决定。这样可以减少参数量,提高模型的泛化能力。
最后,为了避免”expert collapse”,作者增加了balance loss \(\mathcal{L}_{expbal}:=\alpha_1\sum_{i}{f_iP_i}\)
其中$\alpha_1$是超参, $f_i$是第$i$个expert被选中的频率(经过归一化),$P_i$是router给第$i$个expert的平均logit值。
同时,为了考虑实际训练场景,若干个expert会部署到一个device上,我们希望尽可能平均每个device的workload,所以作者提出了device balance loss \(\mathcal{L}_{devbal}:=\alpha_2\sum_{i}{f_i'P_i'}\)
其中$\alpha_2$是超参,$f_i’$是第$i$个device上的expert的$f$的平均值,$P_i’$是第$i$个device上的expert的$P$的平均值。
实际运用中,会采用比较小的$\alpha_1$和比较大的$\alpha_2$。