SQA-019
[Paper] Momentum Contrast for Unsupervised Visual Representation Learning
本文名为 MOCO, Kaiming 在 Facebook 的力作.
本文更早于 SimCLR, 提出了使用 momentum 的方法来做 contrastive learning.
Problem
做 contrastive learning 需要很多负例会效果比较好, 但是这样就必须要大 batch size. 能不能让这两个不矛盾呢?
Method
本文 formulation 如下: 每次 contrastive 是给一个 query 和一些 key representation. 其中 query 和 key 可以是不同的网络提取的特征.
key 的网络有几种选择: 直接使用 query net, 使用 memory bank (过去的某个 query net), 以及本文提出的 momentum encoder.
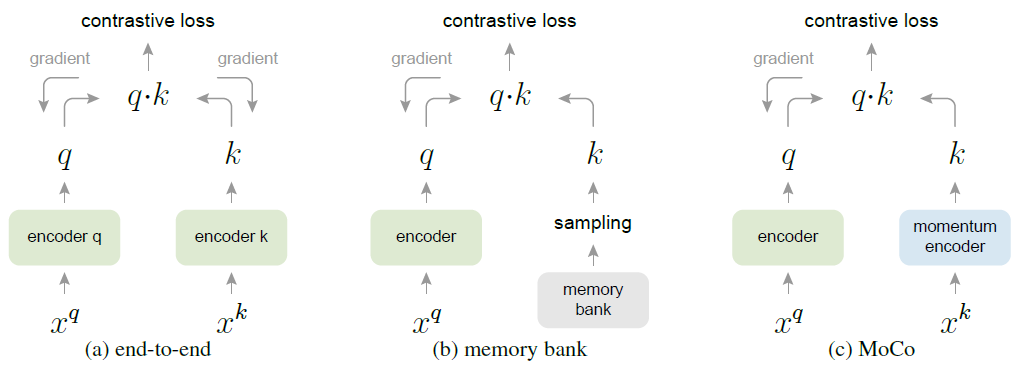
其中注意, 对 contrastive loss (InfoNCE) 做梯度下降的时候, 也会更新 momentum encoder 传过来的那一份.
换句话说, 每次
\[\theta_k \leftarrow m\theta_k + (1-m)\theta_q\]的时候, $\theta_q$ 那一份是会被更新的.
好处: 不仅让 representation 更加 consistent, 同时也可以获得过去的 key 作为负例. (这里的 key 维护一个 queue)
实验结果发现更平滑的 momentum (large $m$, such as 0.999) 会更好.
Configurations
使用的两个 aug 类似 SimCLR, 是 random crop, color jitter, flip, random grey scale.
数据集考虑 ImageNet 和 Instagram-1B. (这个小)
模型使用 ResNet-50 (还有 2x, 4x)
训练之前还有 pretext task, 不知道具体是什么
网络输出的东西过 L2 norm 后作为 feature.
BN
Batch Norm 会作弊: 具体来说, 如果有多个机器, 那么同一个机器的 batch 信息可以用来作弊.
这是因为 query 和 key 通常在同一个机器导致的?
解决方法是对于所有 key, 我们 shuffle 一下再分到不同机器上.
Hyperparameters
温度 0.07. 剩下的不写了, 请欣赏调参大师

包括 Linear eval 的也是. 注意 weight decay 是 0.
Experiments
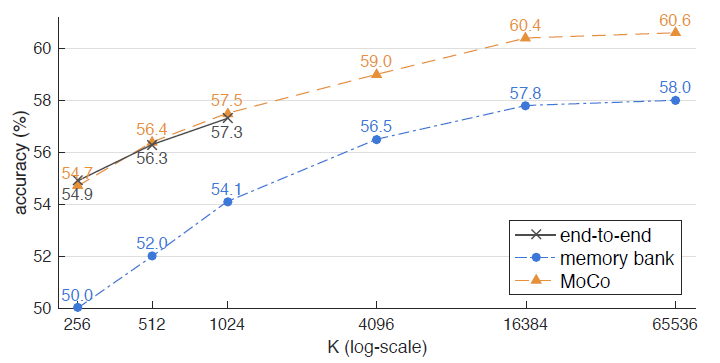
这个是三种不同 key network 的对比. 可以看到 momentum encoder 效果最好.
然后还做了很少的 transfer learning 实验. 没仔细看也每太看懂, 反正应该挺吊的