SQA-018
[Paper] Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
本文又称 Stable Diffusion 3.
Flow-Matching & Diffusion
这里统一了 flow 和 diffusion. ablate 了:
- Trajectory: Linear/Cosine
- $t$-sampling in training
t-schedule
这里对所有 schedule, 都调整 weight 使得 effective weight = 1.
- Log-norm: $u\sim \mathcal N(\mu, \sigma^2), t=\log\dfrac{t}{1-t}$
- Mode: (with parameter $s$) $u\sim \mathcal U[0, 1], t=1-u-s(\cos^2(\dfrac \pi 2 u)-1+u)$
- 这里 $s=0$ 就是 uniform
- CosMap: 希望和 cosine trajectory 的 log-snr 对上. $u\sim \mathcal U[0, 1], t=1-\dfrac{1}{\tan(\frac\pi 2 u)+1}$
Text-to-Image Architecture
基于 DiT 改的. 名字叫做 Multimodel-DiT Block, 简称 MM-DiT. 使用 $p=2$
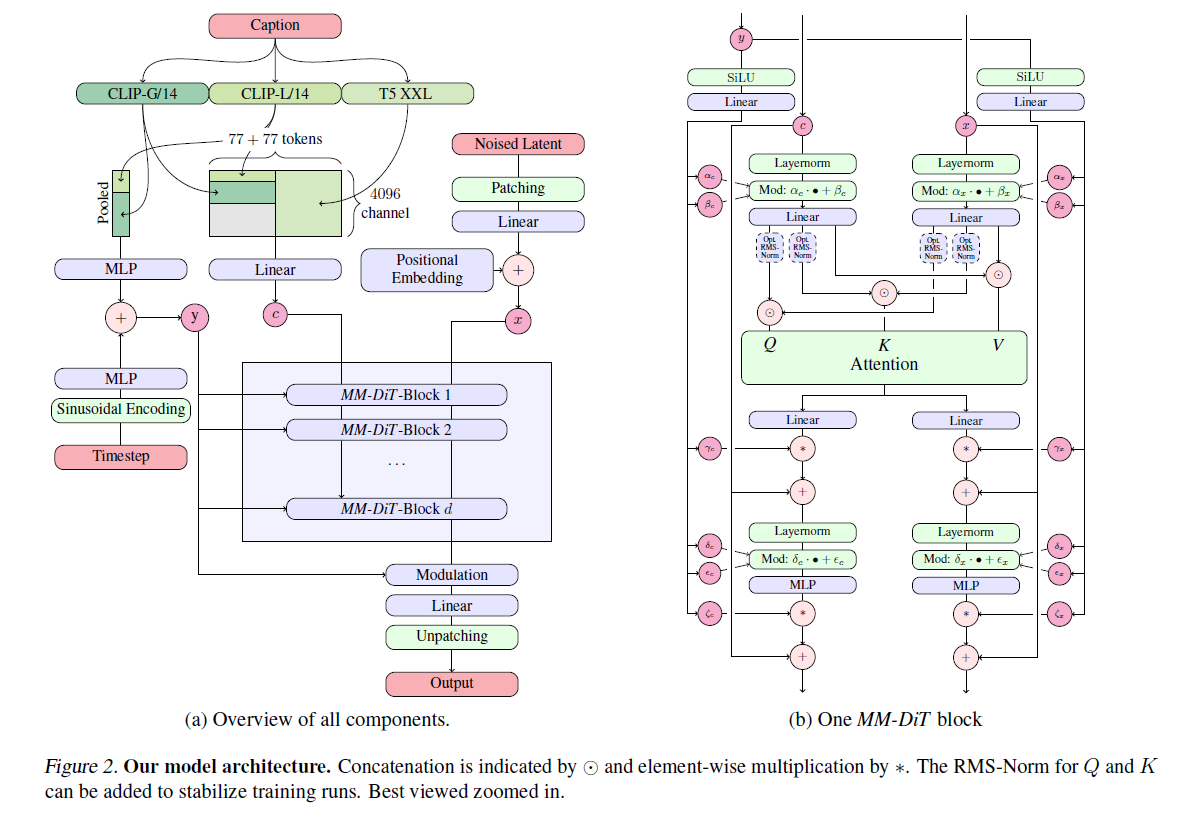
如果没理解错的话, 对于 text prompt 使用三个 encoder, 然后分别视作和 time condition 同样的东西和一个正经的 condition.
然后内部也搞了一通. 关键在于, 对 condition 和 latent 用两个 modulate (平移参数), 然后一起 attention
这个多数没深意
默认配置: 对于深度 $d$, 使用 hidden dim $64\cdot d$, 以及 $d$ 个 attention heads. 略唐
Experiments
Protocol
先在 ImageNet 和 CC12M 上面 pretrain, 看带和不带 EMA 模型的 1. valid loss 2. CLIP score 3. FID
We calculate the FID on CLIP features as proposed by (Sauer et al., 2021). All metrics are evaluated on the COCO-2014 validation split (Lin et al., 2014).
如果做 high-resolution, 就在高清图片上 fine-tune.
Ablations
训了 61 个模型. 没卡.
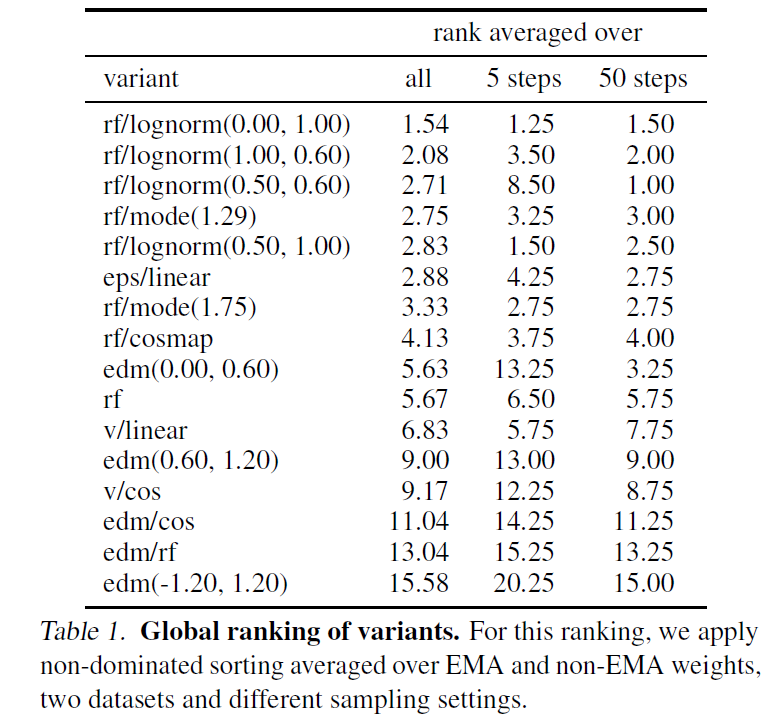
上面是 5 steps 和 50 steps 的结果. 这个步数这么少倒是挺惊讶的
发现 rf/lognorm(0, 1) 普遍很好.
Improved Autoencoders
这里把 AE 的 channel 数增加到 16 维.
Improved Captions
也就是数据集里面的 text 标注. 使用 CogVLM 重新生成了一半, 让质量变高一些
然后大规模训练之前 filter 了一下 data
QK-normalization
fine-tune 的时候没有的话会飞. 应该就是把 K, Q 在 attention 之前 normalize 一下
反正还有一些别的 trick, 但我懒得看了, 反正我们又不训
Change of Position Encoding
提高分辨率之后要改. 说的是用 a combination of extended and interpolated position grids which are subsequently frequency embedded
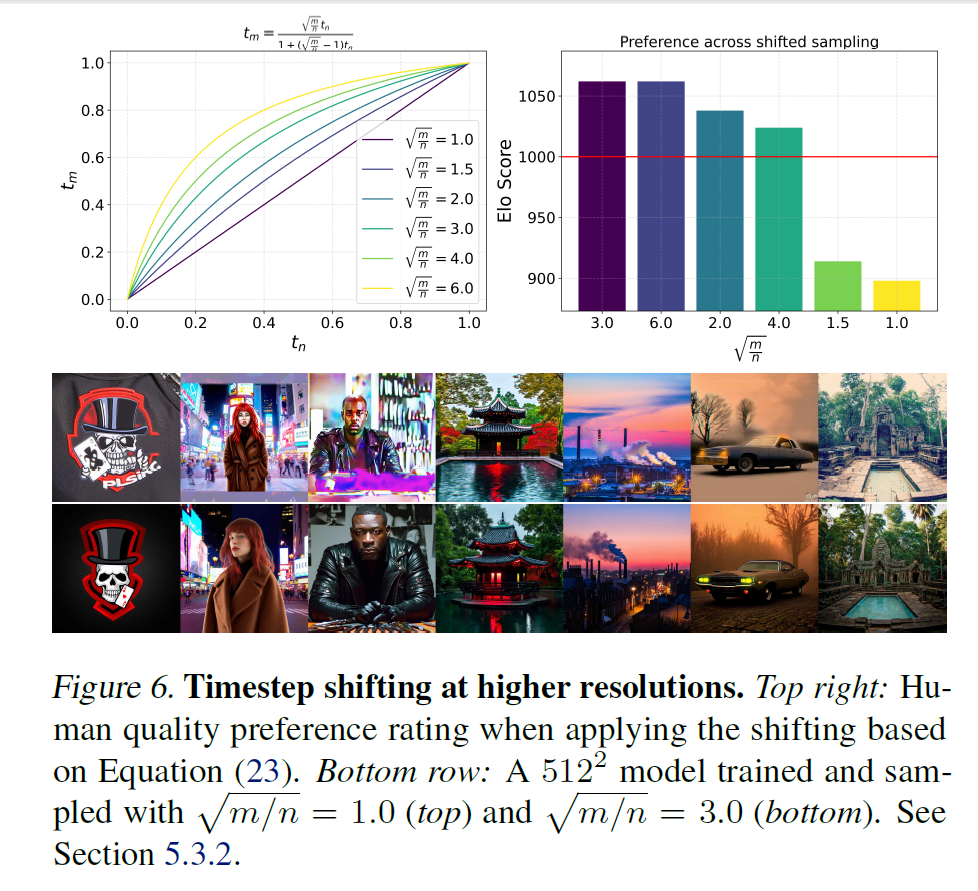
Resolution-dependent shifting of timestep schedules
说提高分辨率之后, $t$-schedule 要相应变化 (理论推导懒得看). 然后这个变化会有个参数 $m$.
最后好像还做了 DPO. 反正事情少
Training techniques
三个 text encoder 每个有 dropout rate 46.3%. 这个数字像活着
说 inference 的时候为了节省计算可以用任意子集的 encoder