ZHH-017
[Paper] MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
最大的贡献在于,统一了repreentation learning和image generation(也就是说在这两个benchmark上都刷到了SOTA)。
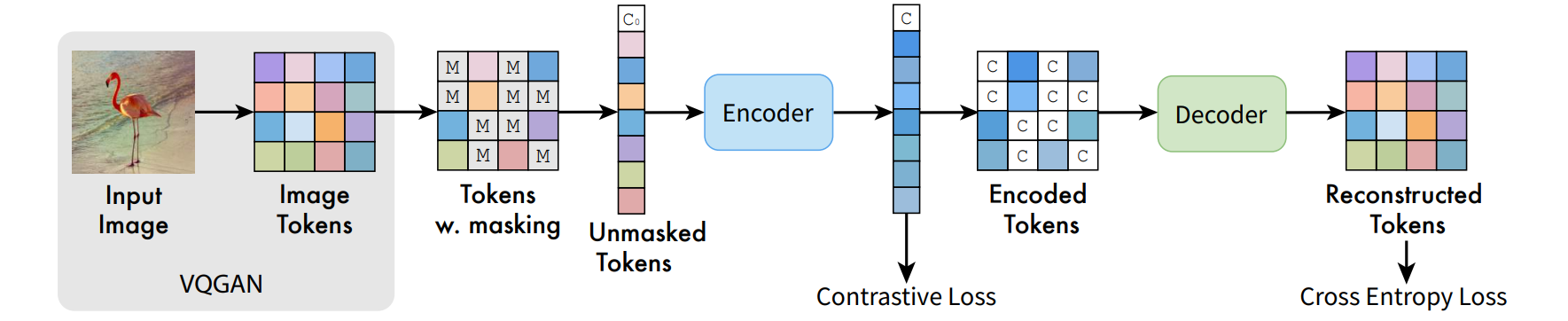
基本思路和MAE非常像。先不管细节,整体可以描述成:首先过一个VQGAN来tokenize;接下来mask掉一定比例的token(从50%到100%,这里和MAE不同),然后选择一些过encoder,之后再重新插入之前mask的部分来喂给decoder,做reconstruction。因为是VQ的token,所以reconstruction loss是cross entropy。
Details
然后细节上有几个不同:
- decoder中处理mask的部分并不是通过mask token完成,而是通过使用encoder得到的额外的class token(注意这一点MAE中也有做,只不过encoder总结出的class token直接append到decoder的输入前面,而不是插入到每一个地方)。
- 中间可以增加一项contrastive loss,称为MAGE-C。注意和SimCLR等传统的contrastive方法不同,因为这里还有一个reconstruction的supervision,所以contrastive loss的positive sample不需要增加那么多的augmentation。
最后注意有一个细节在图里 没有 体现出来:encoder的输入并不是所有unmasked token,而是所有unmasked token加上一部分masked token。实现上,他会先mask掉一些token(比例为 mask_ratio),然后把sequence随机drop掉一半(即 $0.5l$,其中 $l$ 是sequence length,包括mask token和unmasked token),但这一半只能在mask token里面选。如果没说清楚建议看仓库。
在生成的时候使用 MaskGIT 方法:从全部mask的latent开始,喂给encoder-decoder,得到一个概率分布,然后选择置信概率最高的一些token来sample,把这些地方的token变成不是mask再喂给encoder,反复重复。基本思路是这样,实现上会有一些细节。对于representation learning,只需要用encoder就可以了。
Others
实验结果上,unconditional generation几乎可以达到conditional generation的水平。这是合理的,因为这个比较有representation learning特色的任务可能会让模型有很强的unsupervised feature,其效果可以超过class label。
最后,作者解释了为什么要在latent上训练:
- latent会更好的允许模型iterative的生成。设想直接在pixel level上这样做,可能会导致第一次生成的patch太过于模糊;
- 整个encoder网络会更加倾向于学习semantic的信息,而不是low-level的信息。
- latent相邻的部分共同点会比pixel更少,因此可以防止模型作弊。