SQA-016
[Paper] A Simple Framework for Contrastive Learning of Visual Representations
本文又名 SimCLR. Google 做的, 有点调参大师的感觉. (copilot 帮我写的)
Method: Contrastive learning
对每张图, 做两个 augmentations, 形成 positive pair.
对一个 batch, 把 $2B$ 张图片都喂进 encoder $f(\cdot)$ 提取特征 $h$. 我们并不直接对 $h$ 做 loss, 而是先过一个 MLP $g(\cdot)$, 然后在 $z$ 上做 loss.
Loss function 为 \(l_{i, j}=-\log\frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{i=1}^{2B}\mathsf 1_{[k\neq i]}\exp(\text{sim}(z_i, z_j)/\tau)}\) 简单来说, 就是在 $2B$ 张图片中, 希望让同一张图片的特征更近. 其中的 sim 使用的是 cosine similarity.
就这么简单.
Data augmentation
使用的是三种的组合: random cropping (then resize to original size), color distortion, and Gaussian blur.
这个选择是有深意的.
Architecture
对不同的模型都能 work. 作者选用 Resnet50.
最后的 MLP 使用一个两层的, 中间有 ReLU. 这个 non-linearity 很重要!
Batch size and optimizer
不使用 memory bank (简而言之, 就是不把之前提的特征取出来作为负例. 因为他卡少, 用的 bs 够大).
使用 4096 bs. 使用 LARS optimizer, 别的可能会不稳定. 唐
Issue of BN
注意 Batch norm 的时候要把每个 device 上的都聚集起来 (也就是使用 Global BN)! 否则正例一定会分到同一个 device 上而被利用.
Ablations
这个最少.
Augmentations
看图

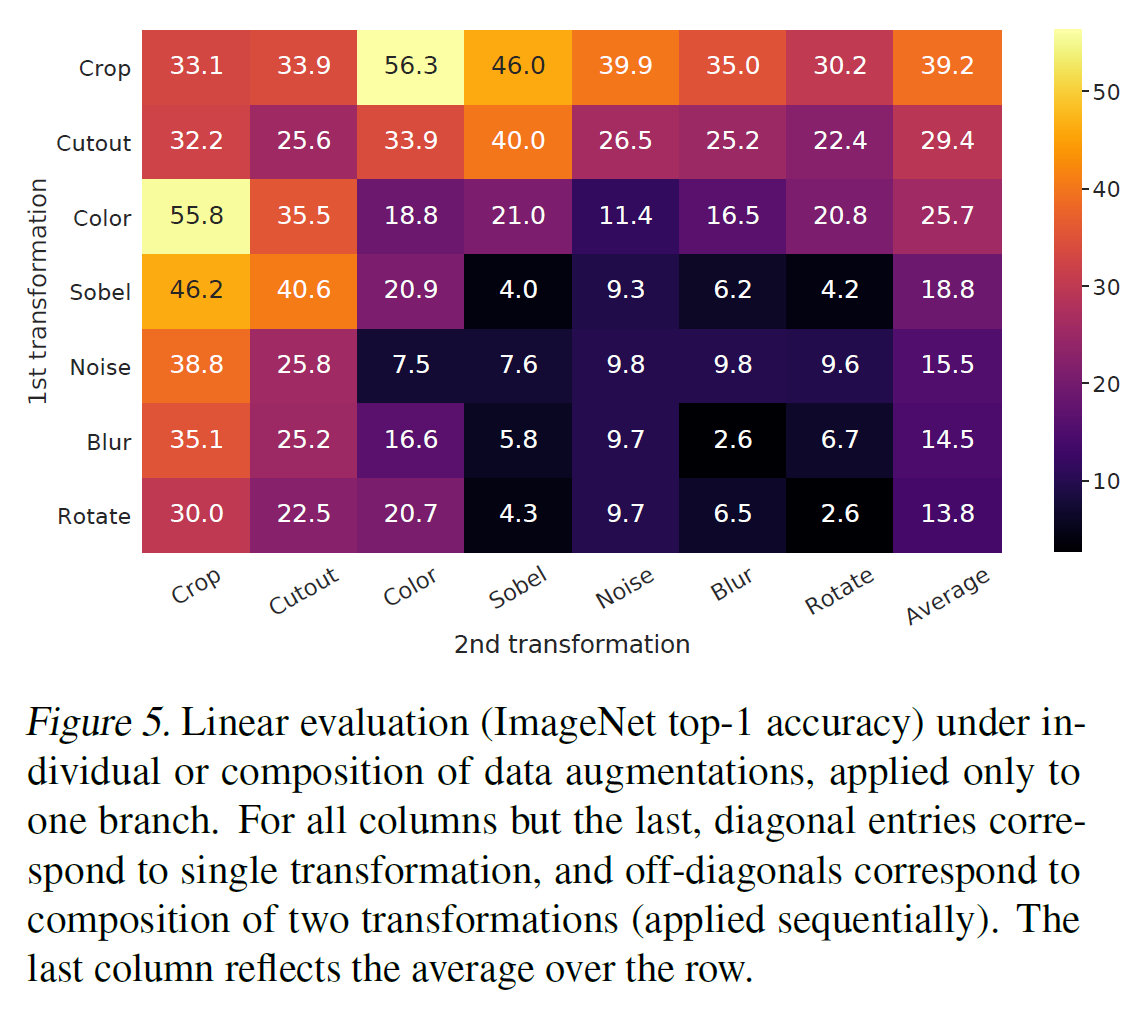
- no single transformation suffices to learn good representations
其中的一个组合: random crop + color distortion 很不错. 猜测原因是, 如果只有 random crop, 模型会利用不同的 patch 更可能是相同的颜色分布的特点.
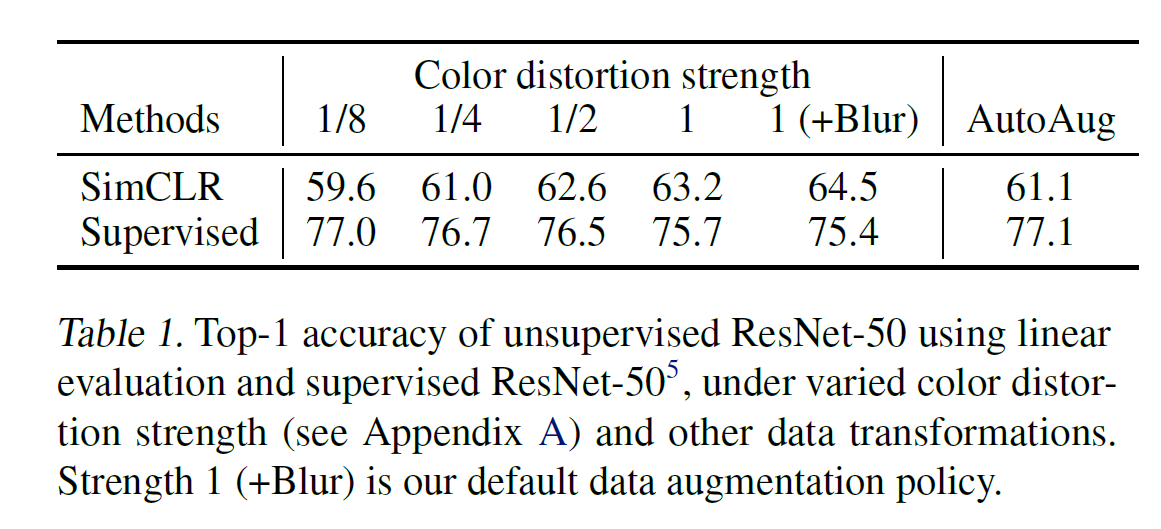
- 实验发现, unsupervised learning 比 supervised learning 需要更强的 augmentations.
Scaling
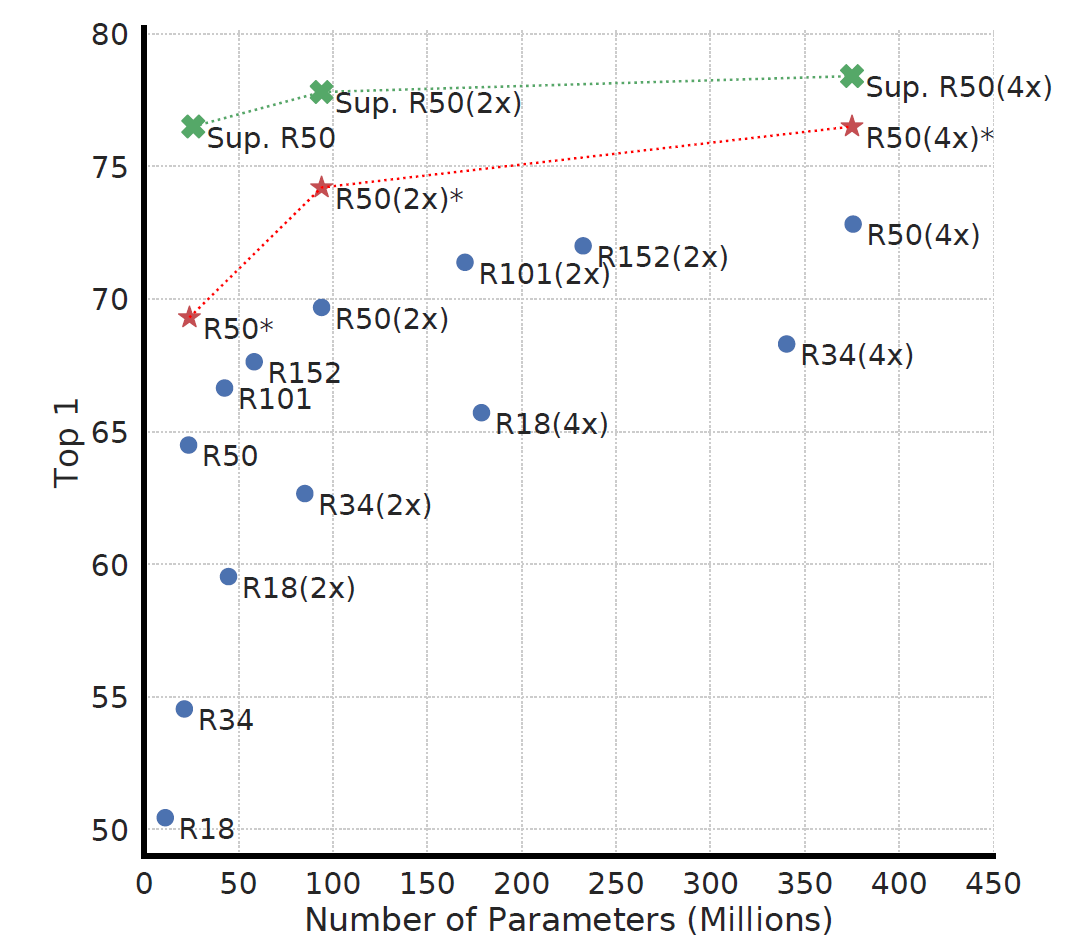
发现 unsupervised learning 模型变大变好的饱和越少.
Non-linearity projection head
反正发现更好了.
Loss function
对其它几种 loss 也测试了一下, 发现 cross-entropy loss 最好.
Batch size & Training
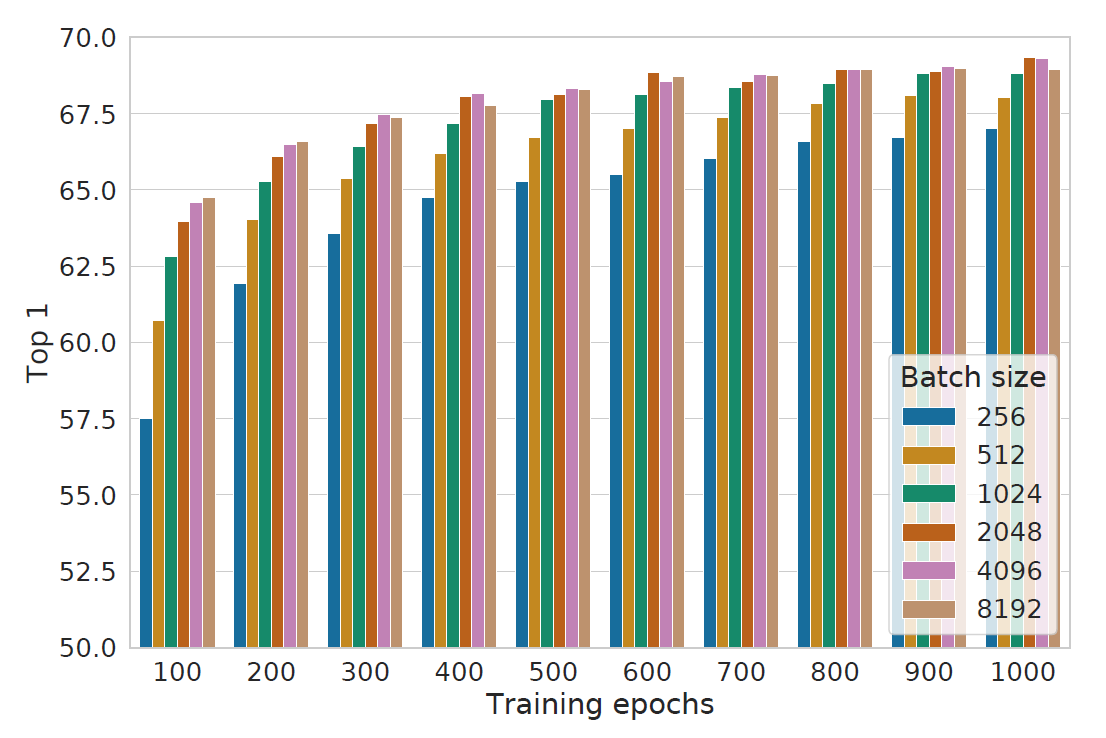
发现大致上 batch size 越大越好, 以及训的越多越好.
SOTA
反正一堆 SOTA, 很牛逼.
Appendix: Details
temperture 最好是 0.5