ZHH-016
[Paper] Masked Autoencoders Are Scalable Vision Learners
大道至简:一句话就可以说明白,我们如何训练一个好的visual representation呢?如图所示,只要给输入mask掉很大的部分(如75%),然后让encoder对剩下的patch(蓝色)进行encode,然后再搞一个lightweight decoder,加上mask token进行decode,然后直接在pixel level上用MSE训练就可以。训练完成之后,把decoder扔了,encoder就可以很好地获得representation。
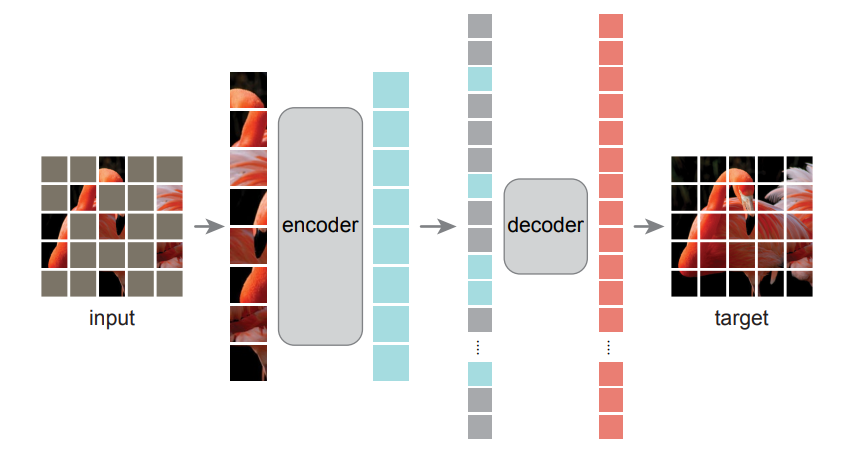
整体上来说,这个设计和BERT很像,但是有以下几个关键的差别:
-
Masking的比例很大。这个巧妙设计是一石二鸟:首先,图片的pixel本身信息很redundant,因此只有大幅的mask才可以让模型学到semantic information,而不是只是通过相邻的patch来cheat;其次,transformer对输入长度计算是平方,因此这样大幅减少输入长度之后显著增加了训练速度。
-
decoder:因为语言的token本身有semantic information,而图片的pixel可以认为是没有,因此这里的decoder不能像BERT一样就是一个projection head;但实际上有趣的是,实验中发现decoder可以很light weight,只用一层很窄的transformer layer就可以。
实验上,MAE在两个任务上表现极其突出:第一个是fine tune,也就是首先用unsupervise方法pretrain,然后supervise finetune,有着很好的表现,甚至超过了直接supervise train from scratch。这是因为ViT在ImageNet这样级别的数据集上最大的问题是过拟合,因此从一个学到了很好的representation的初始状态开始,进行一个很轻的tune,效果反而更好。第二个就是传统的linear probing,这里我们直接把图片全部给encoder,然后把feature经过projection head来分类。
Details & Ablations
一些可能的细节:
Masking Ratio:作者发现linear probing的结果对mask prob很敏感,只有在75%左右到达最好;而对于fine-tuning,mask prob在40%到80%之间都可以。
Loss:注意默认而言,就像BERT一样,我们只对mask的部分进行MSE loss。但实际上发现对于不mask的部分也进行loss,效果只是稍微下降。
Encoder:一个很常见的问题就是,为什么我们只让encoder看不被mask的patch,而不是把剩下的用mask token的形式放进去呢?第一个原因是,这样可以减少计算量;但这不是全部的故事。实验上发现,如果在encoder里使用mask token,linear prob的效果会大打折扣。这就是因为encoder在训练的时候输入都是有很多mask的,这会导致真正做linear prob的时候全是干净的图片,encoder反而“不适应”了。
Prediction Target:这个是一个很小的细节,如果要刷点可能要注意一下?predict的pixel如果normalize,那么效果会更好。具体可以参考论文。
Mask Strategy:还有一个可能的疑惑,也就是随机mask掉一些patch会不会不是最优的?一些可能的思路包括,mask掉一块一块的patch(称为block masking),或者隔一个patch mask一个(称为grid masking)。实验上,还是随机的效果最好。好像也没有解释?