SQA-014
[Paper] Emerging Properties in Self-Supervised Vision Transformers
第一次进军 representation learning, 写的肯定不太好, 也有很多看不懂的地方.
本文又称 DINO. Facebook 做的, 多数不是调参大师
本文训的 ViT 提取的特征仅使用 k-NN 算法就能把 ImageNet 上的分类做到 78.3%, SOTA! 这个是弱的
还提到这一套方法不仅对 transformer 有效, 对 resnet 50 也有效

Problem to tackle
Transformers 很牛逼, 但没展现出比 CNN 更好: 它们其实算得快, 效果也就那样, 而且它们提取的特征通常不好.
但是上面说的特征是基于 supervised learning 的! 注意到, 在 NLP 中基本上都是 self-supervise 的 (BERT / GPT).
本文就搞了一个 ViT 的自监督训练版本. (DINO: self-distillation with no labels). 名字起得不错
提的特征比 supervised CNN 还要好
Method: SSL (self-supervised learning) with knowledge distillation
记号
一般地, 对于 teacher $\theta_t$ 和 student $\theta_s$, distillation 希望 student 的输出 match teacher 的输出.
记 $g_{\theta}$ 是网络输出, 概率 $P_s/P_t$ 是对输出取 softmax, $\tau$ 表示温度
Distillation
Distillation 一般会用 cross-entropy loss
\[\min\limits_{\theta_s} H(P_t(x), P_s(x))\]其中 $H(a, b) = - a \log b$
但是直接 distill 比较唐, 我们使用聪明一点的办法: 对数据, 考虑使用一些 global view 和 local view.
对于 ImageNet, 我们使用的 global view 一般是两张 224x224 的 crop (cover 大于 50%); 而 local view 是 96x96 的 crop (cover 小于 50%).
我们的想法是, 让 student 对任何一个 view 的输出去 match teacher 的 global view 的输出. 于是 loss 长成这样:
\[\min\limits_{\theta_s} \sum\limits_{x \in \{x_1^g, x_2^g\}} \sum\limits_{x' \in V, x' \neq x} H(P_t(x), P_s(x'))\]文中 propose 了两种取 $V$ 的方式: 一种是只取两个 global view, 另一种是 2 global + 10 local (称为 multi-crop).
Self-distillation
但是我们现在没有 teacher model, 那很简单就是用 student model 的历史作为 teacher model.
文中 ablate 了好几种取历史的方法, 见后面
Architecture
注意到 $g=h\circ f$, 其中 $f$ 是 backbone, $h$ 是 projection head. 特征指的就是 $f$ 的输出.
这里使用 $h$ 为三层 MLP, hidden dim=2048, 还使用了一些 normalize 层. 懒得研究了
文中说这个网络是 BN-free 的, 不知道屌不屌
Tricks
他 trick 最少
Avoiding collapse
使用了 centering 和 sharpening
- centering: $g_t(x)\leftarrow g_t(x)+c$, 其中 $c$ 是对 batch 平均的 EMA
- sharpening: 把 teacher 的温度调低
centering 防止一个 dimension dominate, 但 encourage collapse to uniform; sharpening 相反.
所以结论是一起上.
Details
Technical details
follow DeiT, 使用 patch size 8/16, 使用 cls token
weight decay 还有 cosine schedule. 唐
$\tau_t$ 还 tmd 有 warmup schedule, 像活着
Evaluation details
-
linear evaluation: 用一个 MLP 在 frozen 特征上做分类, 其中训练用了 random resize crop 和 horizontal flip, 但是测试只用了 center crop
-
fine-tune evaluation: fine-tune feature on downstream task
文中提到, both evaluations are sensitive to hyperparameters, and we observe a large variance in accuracy between runs when varying the learning rate for example. 话最能蚌
- k-NN evaluation: 全都使用 $K=20$. 注意到只有使用 ViT + self-supervised learning 才能让 k-NN 和 linear 肩并肩
本文还做了很多别的 benchmark, 但是我就会

Ablations
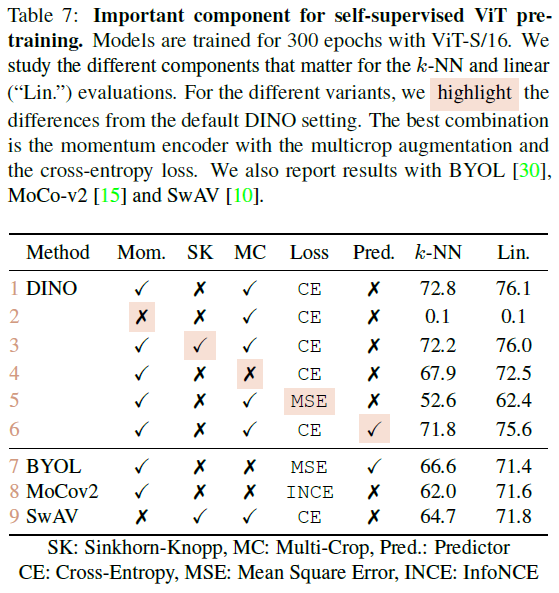
可以看出 Momentum encoder, multi-crop 和 cross-entropy loss 很重要
patch size: 越小越好 (5<8<16)
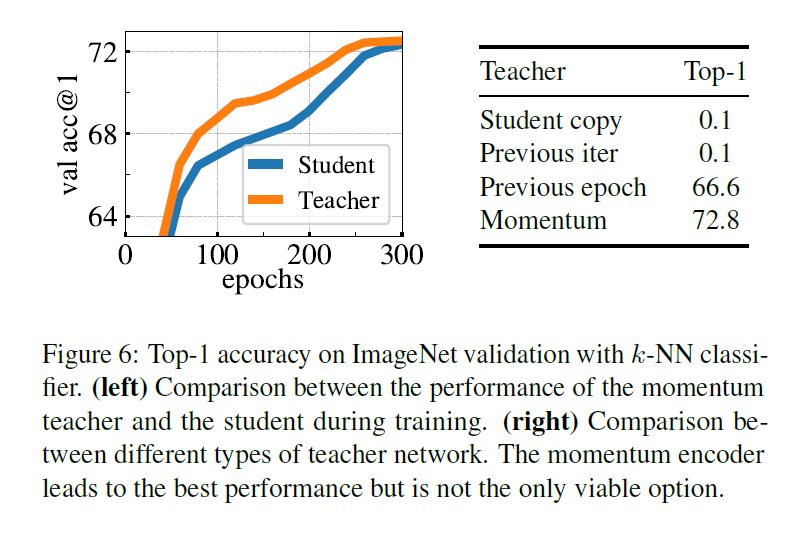
Building teacher from student: 用 student ema 最好. 其中 teacher 的表现比 student 好. 这个挺合理!
multi-crop: 涨了两个点, 然后训练时间还减半, local-to-global 牛逼!
batch size: 越大越好
Appendix
还没看