SQA-013
[Paper] Scalable Diffusion Models with Transformers
本文又称 DiT. 主要把 diffusion 的骨架换成了 transformer, 在 ImageNet 256 & 512 上刷
使用 GFLOPs 衡量计算复杂度 ($10^9$ float-point operations)
核心技术和根基:
- iDDPM, 其中同时预测每部的均值和方差. 均值就用 $L_{simple}$ 来训练, 而方差用 KL 散度的 loss 来训练
- Latent Diffusion Model
- Classifer-free guidance
Technical Details
- Patchify: 对 latent (32x32x4 $I=32$), patchify 成 $(I/p)^2$ 个 token. 主要采用 $p=2,4,8$
- position embedding: 用了 ViT 的 position embedding, sin-cos version
- DiT block: 在 ViT 架构基础上加了小但是重要的改动, 可以看图但不建议看, 因为其实看得懂. 有三种 take condition 的方式
- Decoder: 把输出过一个 LN 然后之间 linear 输出成 patch 的形状. 这个初始化为 0
Way of taking condition
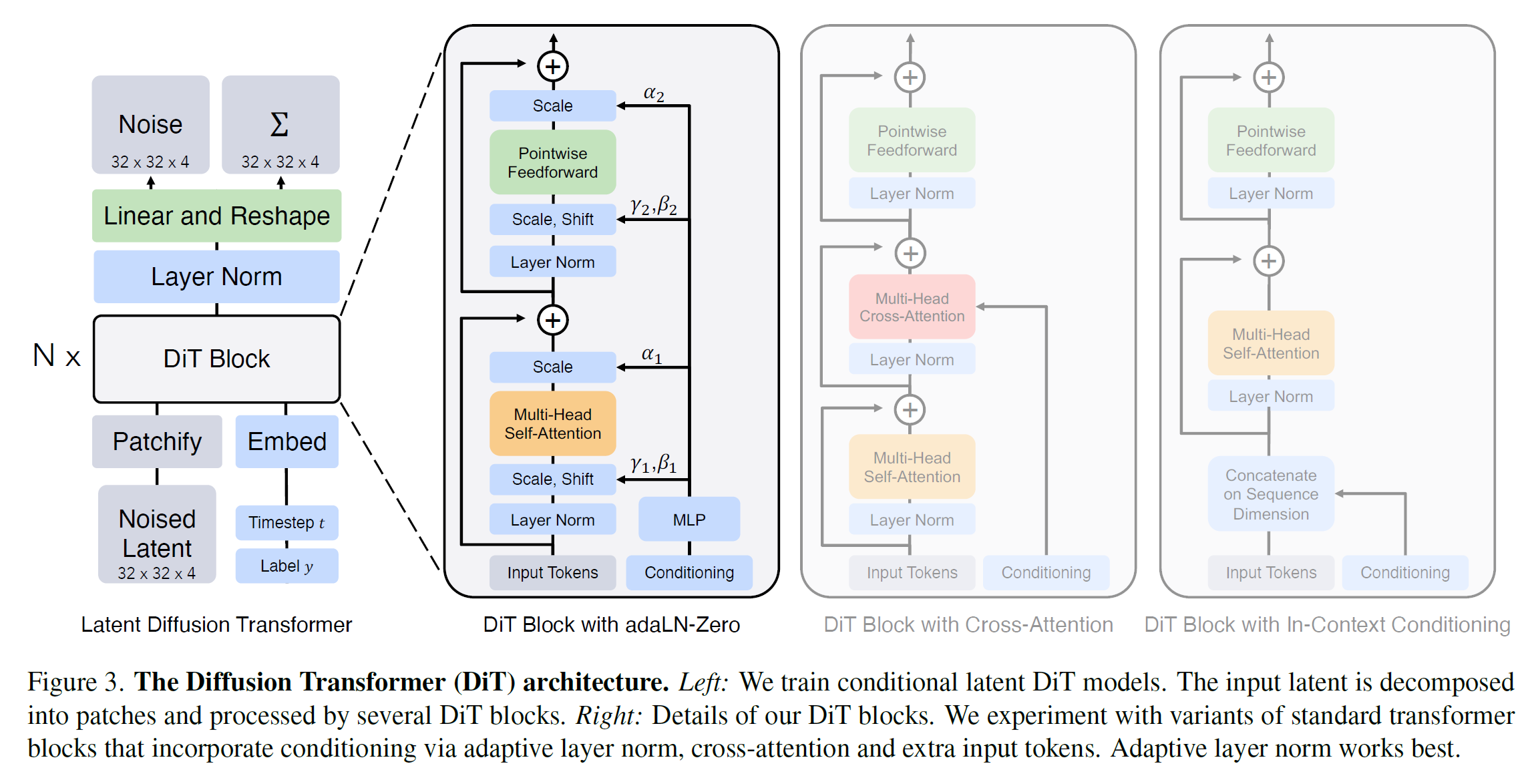
- In-context conditioning: 把 vector embedding $t$ and $c$ 作为输入序列的两个额外的 token (类比 cls in ViT)
- Cross-attention block: 看懂了
- AdaLN block: 随便吧
- AdaLN-zero block: 好像是上面那个搞了一点 zero initialization 什么的, 最知道
其中 AdaLN-zero 明显好. condition 的方式很重要!

Experimental Details
DiT-XL/2表示 patch size 为 2- 不需要 learning rate warmup
- AE 用的是 pretrained VAE (from Stable Diffusion), downsample by 8 倍
- 1000 步训练时间步骤, 0.9999 EMA, eval step 250 (DDPM sampler)
- 大部分和 ADM 相同
Results
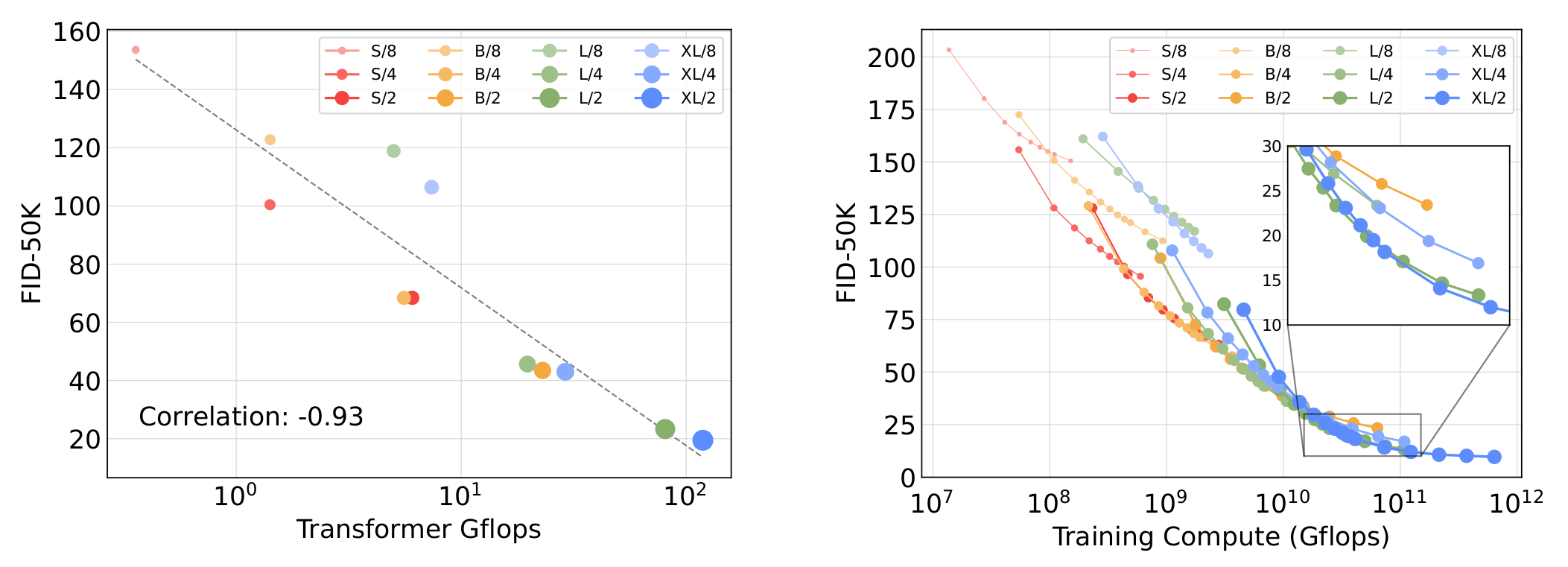
- 相同模型大小, $p$ 越小越好 (GFLOPs 也最大)
- GFLOPs 的 scaling law!
- 越小的模型要训的多
Appendix
Three-channel guidance: 只对 latent 前面三个 channel 做 guidance, 深意在哪?
和正常的效果差不多