SQA-011
[Paper] IMPROVED TECHNIQUES FOR TRAINING CONSISTENCY MODELS
本文改进了 consistency training, 以至于能超过 consistency distillation 的效果! 弱
Problems: LPIPS metric
LPIPS 和 Inception V3 的训练相似性, 导致了可能的 bias, 可以认为有点作弊. 以及 LPIPS 会引来更多的训练计算.
Improvements
- weight in loss
original: $\lambda(\sigma_i)=1$. New: $\lambda(\sigma_i)=\frac{1}{\sigma_{i+1}-\sigma_i}$
对于 $\sigma_i$ 的选择, 我们发现这个权重在 $\sigma$ 越大的时候越小. 也就是让接近数据点更重要.
- Noise embedding
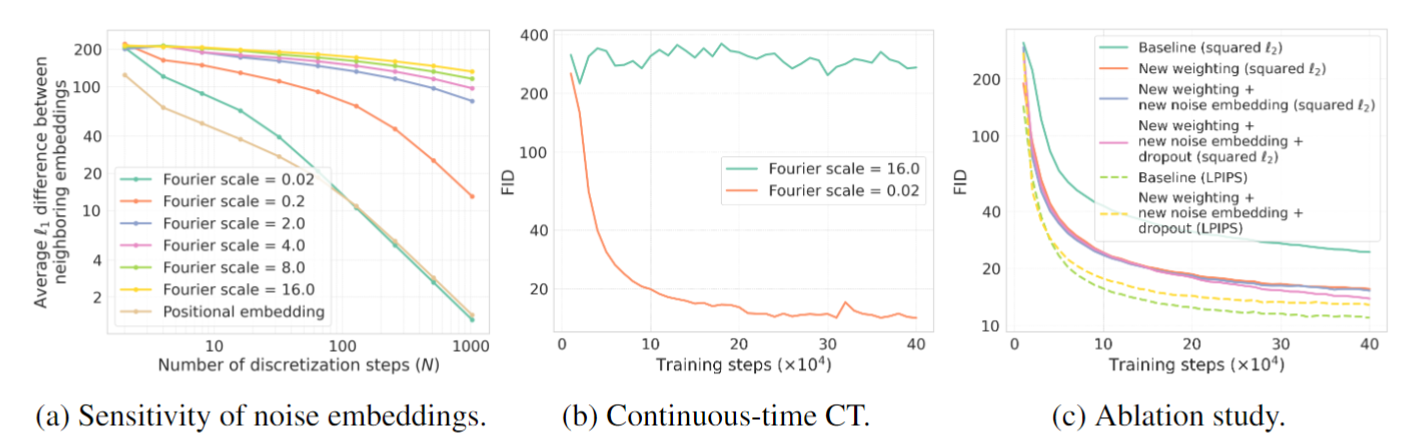
要点在于让 time condition 更加不 sensitive.
使用更不 sensitive 的 noise embedding 能让原来不收敛的 continuous time training 也能收敛. (Fourier scale $16\rightarrow 0.02$)
discrete time training 也能受益但没有这么关键.
- Dropout
一般 0.3 就很好. 注意, 需要保证 teacher 和 student 的 dropout rng 一致.
以上三点就能让 $L_2$ norm 上面的效果显著提升.
- EMA decay for $\theta^-$
文章里面说前一篇论文公式推错了, 只有 EMA decay 为 0 ($\theta=\theta^-$) 的时候才对.
实际上这么做 (就是使用同一个网络 + stop grad) 显著提升效果
- New metric: Psuedo-Huber
可以看作是 $L_1, L_2$ norm 的中间者.
- More robust to outliers! This reduces variance in training
- 一般 $c=0.00054\sqrt d$, where $d$ is dim of output. 对于 CIFAR10, $c=0.03$
- $N$ schedule
从原来的 $s_0=2, s_1=150$ 增加成 $s_0=10, s_1=1280$, 对于 LPIPS 之外的 measurement 明显变好
schedule 选择每过一会把 $N$ 翻倍.
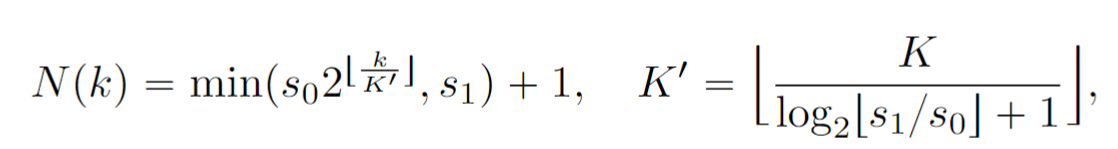
- Noise schedules
训练的时候本来是 uniform sample $\sigma$. 现在我们找一个分布 $p(\sigma_i)$.
Inspired by EDM, 采用了下面的分布

Other details
use lr 1e-4 and RAdam optimizer, batch size 1024 and ema 0.99993
对于两步 sampling, 采用的 noise level 是 0.821