SQA-002
[Paper] PROGRESSIVE DISTILLATION FOR FAST SAMPLING OF DIFFUSION MODELS
PROGRESSIVE DISTILLATION FOR FAST SAMPLING OF DIFFUSION MODELS
present new parameterizations of diffusion models that provide increased stability when using few sampling steps; and present a method to distill a trained deterministic diffusion sampler, using many steps, into a new diffusion model that takes half as many sampling steps
Problem
With no condition (no label or no text prompt), diffusion models’ sampling speed is slow.
Method
Progressive Distillation

- distillation 的时候模型架构不变
- 要求 sampling process deterministic (no noise)
- 只需要对 discrete time steps 进行 distillation
- distill 速度和训练一个差不多
Results: 在 distill 到 4-8 步的时候仍然能取得很好的效果!
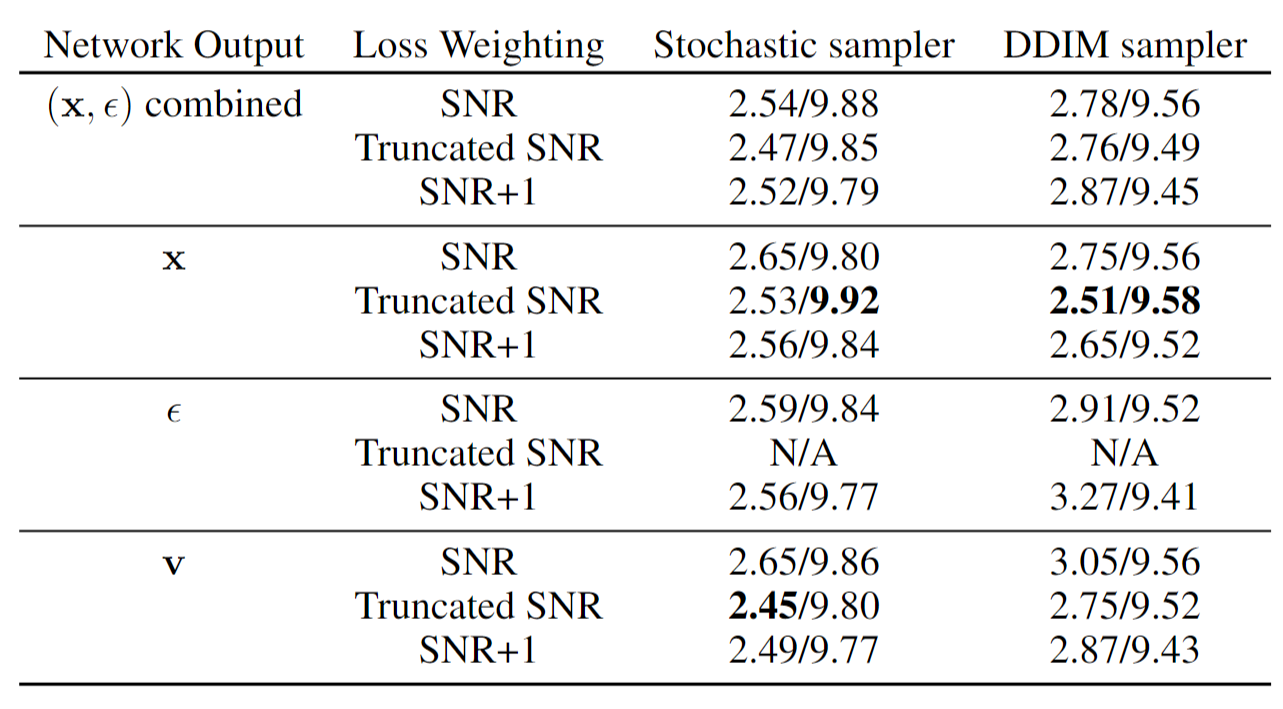
Model parameterization
之前直接预测 $\epsilon$, 但对于 distillation 不适合 (因为步数少的时候前几步很重要)
提出了三种预测目标:
- predict $x$
- predict both $\tilde{x}{\theta}(z_t)$ and $\tilde{\epsilon}{\theta}(z_t)$ , and set
- predict $v=\alpha_t\epsilon-\sigma_t x$
此外, 还基于目标提出了三种权重函数:
Recall loss function $L_{\theta}=\mathbb{E}{\epsilon, t}[w(\lambda_t|\hat{x}{\theta}(z_t)-x|_2^2)]$
其中 $\lambda_t=\log[\alpha_t^2/\sigma_t^2]$ is log signal-to-noise ratio
- SNR: (classical) $w(\lambda_t)=\exp(-\lambda_t)$
- truncated SNR: \(L_{\theta}=\max(\|x-\hat{x}_t\|_2^2, \|\epsilon-\hat{\epsilon}_t\|_2^2)=\max\big(\frac{\alpha_t^2}{\sigma_t^2}, 1\big)\|x-\hat{x}_t\|_2^2\)
- SNR+1 weighting: \(\|v_t-\hat{v}_t\|_2^2=(1+\frac{\alpha_t^2}{\sigma_t^2})\|x-\hat{x}_t\|_2^2\)
Results:
Technical Details
The paper distill on a DDIM model, halving the number of sampling steps.
- DDIM 的 sampling 是 deterministic 的
In distillation: we sample this discrete time such that the highest time index corresponds to a signal-to-noise ratio of zero, i.e. $\alpha_1 = 0$, which exactly matches the distribution of input noise $z_1 \sim N (0, I)$ that is used at test time. We found this to work slightly better than starting from a non-zero signal-to-noise ratio as used by e.g. Ho et al. (2020), both for training the original model as well as when performing progressive distillation.