ZHH-011
[Paper] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
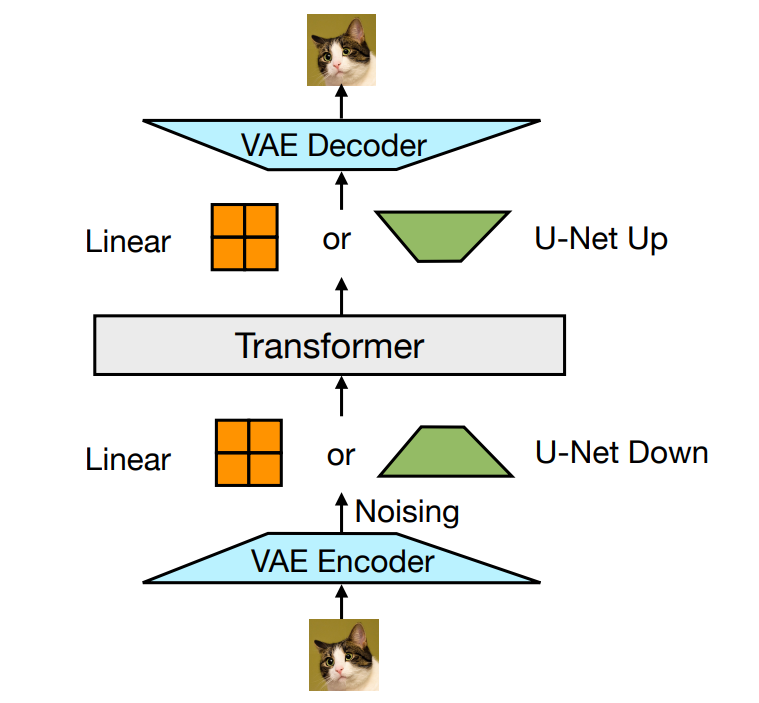
图片和文本的latent放在同一个transformer里;对于文本,transformer的输出直接投影为next token的categorical distribution;对于图片,transformer的输出是一个latent,然后这个latent通过U-net来作noise prediction(噪声就加在这个latent上)
训练的loss就是LM loss和diffusion loss(加权)加起来。