ZHH-008
[Paper] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
这篇文章研究了一种特殊的tokenizer,encode的时候大致是在feature map上构建一个pyramid,而decode的时候则根据不同等级的信息逐渐生成feature map。这个tokenizer也是VQ的。这个Tokenizer的主要好处是,它的latent理论上更好学习,因为图片本身在scale上就有autoregressive的性质。
这是整体的结构,注意生成token的attention mask:
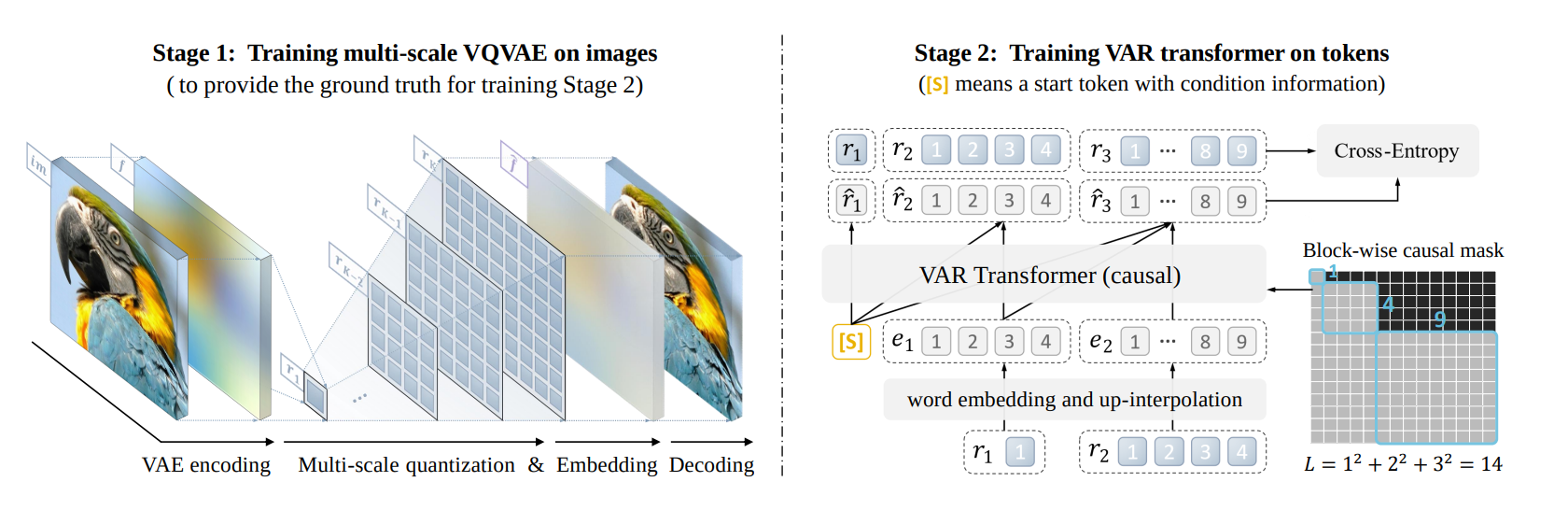
下面是它的encoder和decoder的结构:
