ZHH-007
[Paper] An Image is Worth 32 Tokens for Reconstrcution and Generation
目标是生成和位置无关的latent representation(或者说是token)。想法很简单:latent tokens和输入一起放到一个Transformer里面,然后输出的时候只留下latent tokens,这是encoder;而经过quantize之后,再加上图片对应的mask tokens,一起过decoder,希望最后图片的mask token变成原来的图片。
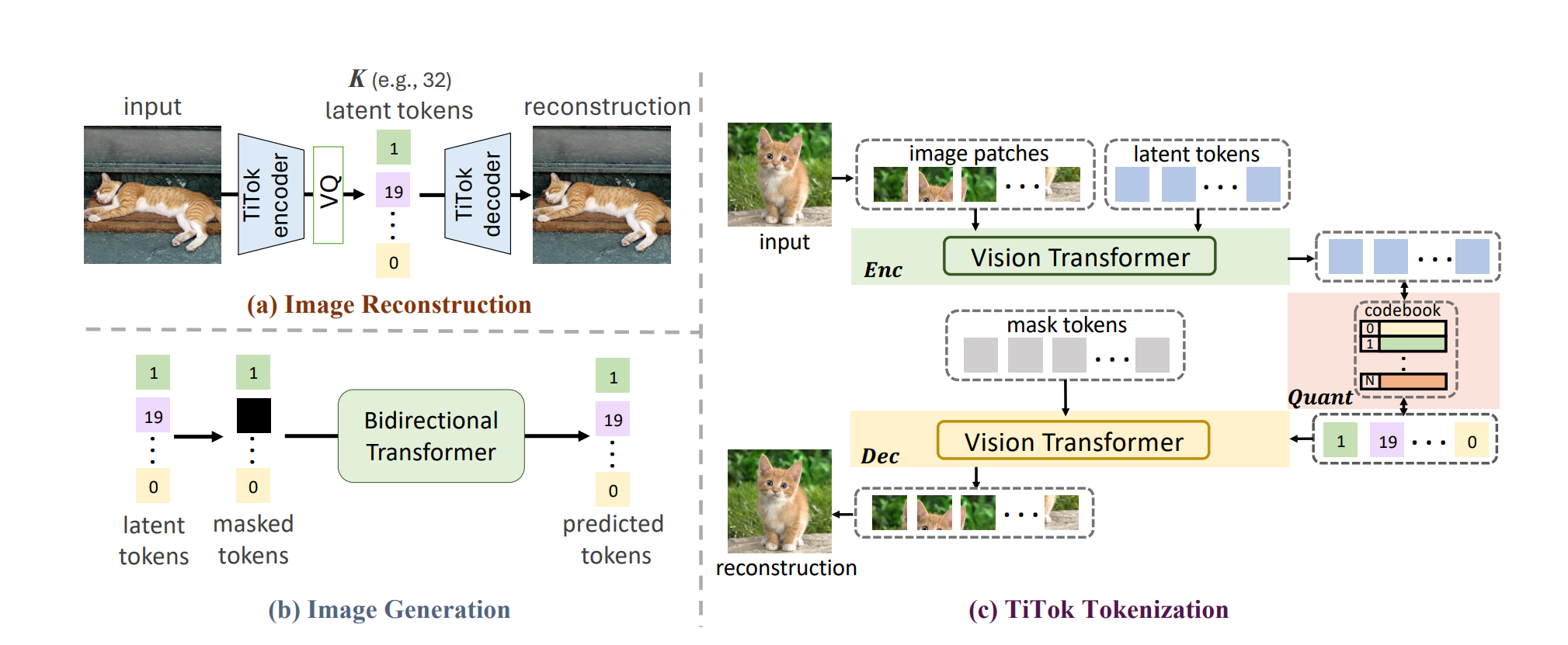
但想一想这个就很难训练,因此作者采用了two-stage training:首先,使用最先进的VQ-GAN的latent code,然后只训练encoder的cross-entry loss和字典的loss;接下来,第二步再finetune decoder。